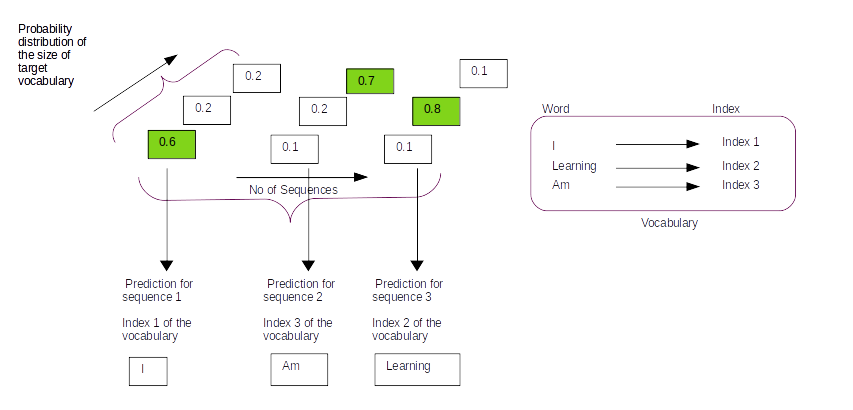
This is the eighth and last post of our series on building a self learning recommendation system using reinforcement learning. This series consists of 8 posts where in we progressively build a self learning recommendation system.
- Recommendation system and reinforcement learning primer
- Introduction to multi armed bandit problem
- Self learning recommendation system as a K-armed bandit
- Build the prototype of the self learning recommendation system : Part I
- Build the prototype of the self learning recommendation system : Part II
- Productionising the self learning recommendation system : Part I – Customer Segmentation
- Productionising self learning recommendation system: Part II : Implementing self learning recommendations
- Evaluating deployment options for the self learning recommendation systems. ( This post )
This post ties together all what we discussed in the previous two posts where in we explored all the classes and methods we built for the application. In this post we will implement the driver file which controls all the processes and then explore different options to deploy this application.
Implementing the driver file
Now that we have seen all the classes and methods of the application, let us now see the main driver file which will control the whole process.
Open a new file and name it rlRecoMain.py and copy the following code into the file
import argparse
import pandas as pd
from utils import Conf,helperFunctions
from Data import DataProcessor
from processes import rfmMaker,rlLearn,rlRecomend
import os.path
from pymongo import MongoClient
# Construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument('-c','--conf',required=True,help='Path to the configuration file')
args = vars(ap.parse_args())
# Load the configuration file
conf = Conf(args['conf'])
print("[INFO] loading the raw files")
dl = DataProcessor(conf)
# Check if custDetails already exists. If not create it
if os.path.exists(conf["custDetails"]):
print("[INFO] Loading customer details from pickle file")
# Load the data from the pickle file
custDetails = helperFunctions.load_files(conf["custDetails"])
else:
print("[INFO] Creating customer details from csv file")
# Let us load the customer Details
custDetails = dl.gvCreator()
# Starting the RFM segmentation process
rfm = rfmMaker(custDetails,conf)
custDetails = rfm.segmenter()
# Save the custDetails file as a pickle file
helperFunctions.save_clean_data(custDetails,conf["custDetails"])
# Starting the self learning Recommendation system
# Check if the collections exist in Mongo DB
client = MongoClient(port=27017)
db = client.rlRecomendation
# Get all the collections from MongoDB
countCol = db["rlQuantdic"]
polCol = db["rlValuedic"]
rewCol = db["rlRewarddic"]
recoCountCol = db['rlRecotrack']
print(countCol.estimated_document_count())
# If Collections do not exist then create the collections in MongoDB
if countCol.estimated_document_count() == 0:
print("[INFO] Main dictionaries empty")
rll = rlLearn(custDetails, conf)
# Consolidate all the products
rll.prodConsolidator()
print("[INFO] completed the product consolidation phase")
# Get all the collections from MongoDB
countCol = db["rlQuantdic"]
polCol = db["rlValuedic"]
rewCol = db["rlRewarddic"]
# start the recommendation phase
rlr = rlRecomend(custDetails,conf)
# Sample a state since the state is not available
stateId = rlr.stateSample()
print(stateId)
# Get the respective dictionaries from the collections
countDic = countCol.find_one({stateId: {'$exists': True}})
polDic = polCol.find_one({stateId: {'$exists': True}})
rewDic = rewCol.find_one({stateId: {'$exists': True}})
# The count dictionaries can exist but still recommendation dictionary can not exist. So we need to take this seperately
if recoCountCol.estimated_document_count() == 0:
print("[INFO] Recommendation tracking dictionary empty")
recoCountdic = {}
else:
# Get the dictionary from the collection
recoCountdic = recoCountCol.find_one({stateId: {'$exists': True}})
print('recommendation count dic', recoCountdic)
# Initialise the Collection checker method
rlr.collfinder(stateId,countDic,polDic,rewDic,recoCountdic)
# Get the list of recommended products
seg_products = rlr.rlRecommender()
print(seg_products)
# Initiate customer actions
click_list,buy_list = rlr.custAction(seg_products)
print('click_list',click_list)
print('buy_list',buy_list)
# Get the reward functions for the customer action
rlr.rewardUpdater(seg_products,buy_list ,click_list)
We import all the necessary libraries and classes in lines 1-7.
Lines 10-12, detail the argument parser process. We provide the path to our configuration file as the argument. We discussed in detail about the configuration file in post 6 of this series. Once the path of the configuration file is passed as the argument, we read the configuration file and the load the value in the variable conf in line 15.
The first of the processes is to initialise the dataProcessor class in line 18. As you know from post 6, this class has the methods for loading and processing data. After this step, lines 21-33 implements the raw data loading and processing steps.
In line 21 we check if the processed data frame custDetails is already present in the output directory. If it is present we load it from the folder in line 24. If we havent created the custDetails data frame before, we initiate that action in line 28 using the gvCreator method we have seen earlier. In lines 30-31, we create the segments for the data using the segmenter method in the rfmMaker class. Finally the custDetails data frame is saved as a pickle file in line 33.
Once the segmentation process is complete the next step is to start the recommendation process. We first establish the connection with our collection in lines 38-39. Then we collect the 4 collections from MongoDB in lines 42-45. If the collections do not exist it will return a ‘None’.
If the collections are none, we need to create the collections. This is done in lines 50-59. We instantiate the rlLearn class in line 52 and the execute the prodConsolidator()prodConsolidator() method in post 7 for details. Once the collections are created, we get those collections in lines 57-59.
Next we instantiate the rlRecomend class in line 62 and then sample a stateID in line 64. Please note that the sampling of state ID is only a work around to simulate a state in the absence of real customer data. If we were to have a live application, then the state Id would be created each time a customer logs into the sytem to buy products. As you know the state Id is a combination of the customers segment, month and day in which the logging happens. So as there are no live customers we are simulating the stateId for our online recommendation process.
Once we have sampled the stateId, we need to extract the dictionaries corresponding to that stateId from the MongoDb collections. We do that in lines 69-71. We extract the dictionary corresponding to the recommendation as a seperate step in lines 75-80.
Once all the dictionaries are extracted, we do the initialisation of the dictionaries in line 87 using the collfinder method we explored in post 7 . Once the dictionaries are initialised we initiate the recommendation process in line 89 to get the list of recommended products.
Once we get the recommended products we simulate customer actions in line 93, and then finally update the rewards and values using rewardUpdater method in line 98.
This takes us to the end of the complete process to build the online recommendation process. Let us now see how this application can be run on the terminal

The application can be executed on the terminal with the below command
$ python rlRecoMain.py --conf config/custprof.jsonThe argument we give is the path to the configuration file. Please note that we need to change directory to the rlreco directory to run this code. The output from the implementation would be as below
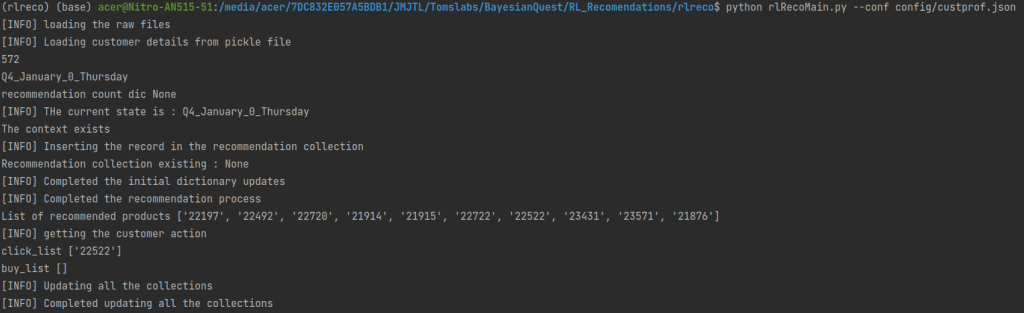
The data can be seen in the MongoDB collections also. Let us look at ways to find the data in MongoDB collections.
To initialise Mongo db from terminal, use the following command

You should get the following output

Now to find all the data bases in Mongo DB you can use the below command
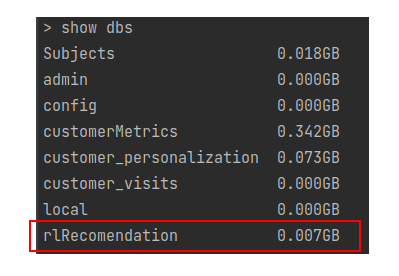
You will be able to see all the databases which you have created. The one marked in red is the database we created. No to use that data base the command used is use rlRecomendation as shown below. We will get the command that the database has been switched to the desired data base.

To see all the collections we have made in this database we can use the below command.
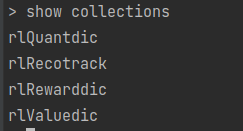
From the output we can see all the collections we have created. Now to see some specific record within the collections, we can use the following command.
db.rlValuedic.find({"Q1_August_1_Monday":{$exists:true} })In the above command we are trying to find all records in the collection rlValuedic for the stateID "Q1_August_1_Monday". Once we execute this command we get all the records in this collection for this specific stateID. You should get the below output.
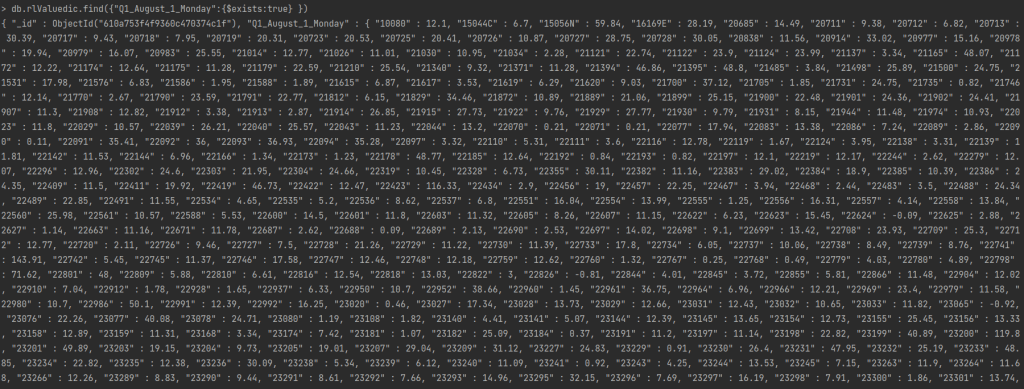
The output displays all the proucts for that stateID and its value function.
What we have implemented in code is a simulation of the complete process. To run this continuously for multiple customers, we can create another scrip with a list of desired customers and then execute the code multiple times. I will leave that step as an exercise for you to implement. Now let us look at different options to deploy this application.
Deployment of application
The end product of any data science endeavour should be to build an application and sharing it with the world. There are different options to deploy python applications. Let us look at some of the options available. I would encourage you to explore more methods and share your results.
Flask application with Heroku
A great option to deploy your applications is to package it as a Flask application and then deploy it using Heroku. We have discussed this option in one of our earlier series, where we built a machine translation application. You can refer this link for details. In this section we will discuss the nuances of building the application in Flask and then deploying it on Heroku. I will leave the implementation of the steps for you as an exercise.
When deploying the self learning recommendation system we have built, the first thing which we need to design is what the front end will contain. From the perspective of the processes we have implemented, we need to have the following processes controlled using the front end.
- Training process : This is the process which takes the raw data, preprocesses the data and then initialises all the dictionaries. This includes all the processes till line 59 in the driver file
rlRecoMain.py. We need to initialise the process of training from the front end of the flask application. In the background all the process till line 59 should run and the dictionaries needs to be updated. - Recommendation simulation : The second process which needs to be controlled is the one where we get the recommendations. The start of this process is the simulation of the state from the front end. To do this we can provide a drop down of all the customer IDs on the flask front end and take the system time details to form the stateID. Once this stateID is generated, we start the recommendation process which includes all the process starting from line 62 till line 90 in the the driver file
rlRecoMain.py. Please note that line 64 is the stateID simulating process which will be controlled from the front end. So that line need not be implemented. The final output, which is the list of all recommended products needs to be displayed on the front end. It will be good to add some visual images along with the product for visual impact. - Customer action simulation : Once the recommended products are displayed on the front end, we can send feed back from the front end in terms of the products clicked and the products bought through some widgets created in the front end. These widgets will take the place of line 93, in our implementation. These feed back from the front end needs to be collected as lists, which will take the place of
click_listandbuy_listgiven in lines 94-95. Once the customer actions are generated, the back end process in line 98, will have to kick in to update the dictionaries. Once the cycle is completed we can build a refresh button on the screen to simulate the recommendation process again.
Once these processes are implemented using a Flask application, the application can be deployed on Heroku. This post will give you overall guide into deploying the application on Heroku.
These are broad guidelines for building the application and then deploying them. These need not be the most efficient and effective ones. I would challenge each one of you to implement much better processes for deployment. Request you to share your implementations in the comments section below.
Other options for deployment
So far we have seen one of the option to build the application using Flask and then deploy them using Heroku. There are other options too for deployment. Some of the noteable ones are the following
- Flask application on Ubuntu server
- Flask application on Docker
The attached link is a great resource to learn about such deployment. I would challenge all of you to deploy using any of these implementation steps and share the implementation for the community to benefit.
Wrapping up.
This is the last post of the series and we hope that this series was informative.
We will start a new series in the near future. The next series will be on a specific problem on computer vision specifically on Object detection. In the next series we will be building a ‘Road pothole detector using different object detection algorithms. This series will touch upon different methods in object detection like Image Pyramids, RCNN, Yolo, Tensorflow Object detection API etc. Watch out this space for the next series.
Please subscribe to this blog post to get notifications when the next post is published.
You can also subscribe to our Youtube channel for all the videos related to this series.
The complete code base for the series is in the Bayesian Quest Git hub repository
Do you want to Climb the Machine Learning Knowledge Pyramid ?
Knowledge acquisition is such a liberating experience. The more you invest in your knowledge enhacement, the more empowered you become. The best way to acquire knowledge is by practical application or learn by doing. If you are inspired by the prospect of being empowerd by practical knowledge in Machine learning, subscribe to our Youtube channel
I would also recommend two books I have co-authored. The first one is specialised in deep learning with practical hands on exercises and interactive video and audio aids for learning
This book is accessible using the following links
The Deep Learning Workshop on Amazon
The Deep Learning Workshop on Packt
The second book equips you with practical machine learning skill sets. The pedagogy is through practical interactive exercises and activities.

This book can be accessed using the following links
The Data Science Workshop on Amazon
The Data Science Workshop on Packt
Enjoy your learning experience and be empowered !!!!