

“Look deep into nature and you will understand everything better”
Albert Einsteen
This is the third part of our series on building a machine translation application. In the last two posts we understood the solution landscape for machine translation and also explored different architecture choices for sequence to sequence models. In this post we take a deep dive into the dynamics of the model we use for machine translation, LSTM model. This series consists of 8 posts.
- Understand the landscape of solutions available for machine translation
- Explore sequence to sequence model architecture for machine translation.
- Deep dive into the LSTM model with worked out numerical example.( This post)
- Understand the back propagation algorithm for a LSTM model worked out with a numerical example.
- Build a prototype of the machine translation model using a Google colab / Jupyter notebook.
- Build the production grade code for the training module using Python scripts.
- Building the Machine Translation application -From Prototype to Production : Inference process
- Build the machine translation application using Flask and understand the process to deploy the application on Heroku
Dissecting the LSTM network
I was recently reading the book ” The Agony and the Ecstacy’ written by Irving Stone. This book was about the Reniassence genius, master sculptor and artist Michelangelo. When sculptuing human forms, in his quest for perfection , Miehelangelo used to spent months dissecting dead bodies to understand the anotomy of human beings. His thought process was that unless he understood in detail how each fibre of human muscle work, it would be difficult to bring his work to life. I think his experience in dissecting and understanding the anatomy of the human body has had a profound impact on his masterpieces like Moses, Pieta,David and his paintings in the Sistine Chapel.

I too believe in that philosophy of getting a handle on the inner working of algorithms to really appreciate how they can be used for getting the right business outcomes. In this post we will understand the LSTM network in depth and explore its therotical underpinnings. We will see a worked out example of the forward pass for a LSTM network.
Forward pass of the LSTM
Let us learn the dynamics of the forward pass of LSTM with a simple network. Our network has two time steps as represented in the below figure. The first time step is represented as 't-1' and the subsequent one as time step 't'

Let us try to understand each of the terms in the above network. A LSTM unit receives as its input the following
c<t-2>: The cell state of the previous time stepa<t-2>: The output from the previous time stepx<t-1>: The input of the present time step
The cell state is the unit which is responsible for trasmitting the context accross different time steps. At each time step certain add and forget operations happens to the context transmitted from the previous time steps. These Operations are controlled through multiple gates. Let us understand each of the gates.
Forget Gate
The forget gate determines what part of the input have to be introduced into cell state and what needs to be forgotten. The forget gate operation can be represented as follows
Ґf = sigmoid(Wf*[ xt ] + Uf * [ at-1 ] + bf)
There are two weight parameters ( Wf and Uf ) which transforms the input ( xt ) and the output from the previous time step ( at-1) . This equation can be simplified by concatenating both the weight parameters and the corresponding xt & at vectors to a form given below.
Ґf = sigmoid(Wf *[xt , at-1] + bf)
Ґf is the forget gate
Wf is the new weight matrix got by concatenating [ Wf , Uf]
[xt , at-1]is the concatenation of the current time step input and the previous time step output from the
bf is the bias term.
The purpose of the sigmoid function is to quash the values within the bracket to act as a gate with values between 0 & 1 . These gates are used to control the flow of information. A value of 0 means no information can flow and 1 means all information needs to pass through. We will see more of those steps in a short while.
Update Gate
Update gate equation is similar to that of the forget gate . The only difference is the use of a different weight for this operation.
Ґu = sigmoid(Wu *[xt , at-1] + bu)
Wu is the weight matrix
Bu is the bias term for the update gate operation
All other operations and terms are similar to that in the forget gate
Input activation
In this operation the input layer is activated using a tanh non linear activation.
C~ = tanh(Wc *[x , a] + bc)
C~ is the input activation
Wc is the weight matrix
bc is the bias term which is added.
operation converts the terms within the bracket to values between -1 & 1 . Let us take a pause and analyse why a sigmoid is used for the gate operations and tanh used for the input activation layers.
The property of sigmoid is to give an output between 0 and 1. So in effect after the sigmoid gate, we either add to the available information or do not add any thing at all. However for the input activation we also might need to forget some items. Forgetting is done by having negative values as output. tanh layer ranges from -1 to 1 which you can see have negative values. This will ensure that we will be able to forget some elments and remember others when using the tanh operation.
Internal Cell State
Now that we have seen some of the building block operations, let us see how all of them come together. The first operation where all these individual terms come together is to define the internal cell state.
We already know that the forget and update gates which have values ranging between 0 to 1, act as controllers of information. The forget gate is applied on the previous time step cell state and then decides which of the information within the previous cell state has to be retained and what has to be eliminated.
Ґf * C<t-1>
The update gate is applied on the input activation information and determines which of these information needs to be retained and what needs to be eliminated .
Ґu * C~
These two informations block i.e the balance of the previous cell state and the selected information of the input activation are combined together to form the current cell state. This is represented in the equation as below.
C<t> = Ґu * C~ + Ґf * C<t-1>
Output Gate
Now that the cell state is defined it is time to work on the output from the current cell. As always, before we define the output candidates we first define the decision gate. The operations in the output gate is similar to the forget gate and the update gate .
Ґo = sigmoid(Wo *[x , a] + bo)
Wo is the weight matrix
Bo is the bias term for the update gate operation
Output
The final operation within the LSTM cell is to define the output layer. The output candidates are determined by carrying out a tanh() operation on the internal cell state. The output decision gate is then applied on this candidate to derive the output from the network. The equation for the output is as follows
a<t> = tanh(C<t>) * Ґo
In this operation using the tanh operation on the cell state we arrive at some candidates to be forgotten ( -ve values) and some to be remembered or added to the context. The decision on which of these have to be there in the output is decided by the final gate, output gate.
This sums up the mathematical operations within LSTM. Let us see these operations in action using a numerical example.
Dynamics of the Forward Pass
Now that we have seen the individual components of a LSTM let us understand the real dynamics using a toy numerical examples.
The basic building block of LSTM like any neural network is its hidden layer, which comprises of a set of neurons. The number of neurons within its hidden unit is a hyperparameter when initializing a LSTM. The dimensions of all the other components of a LSTM depends on the dimension of the hidden unit. Let us now define the dimensions of all the components of the LSTM.
| Component | Description | Dimension of the component |
| LSTM hidden unit | Size of the LSTM unit ( No of nuerons of the hidden unit) | (n_a) |
| m | Number of examples | (m) |
| n_x | Size of inputs | (n_x) |
| C<t-1> | Dimension of previous cell state | (n_a , m) |
| a<t-1> | Dimensions of previous output | (n_a , m) |
| x<t> | Current state input | (n_x , m) |
| [ x<t> , a<t-1> ] | Concatenation of output of previous time step and current time step input | (n_x + n_a, m) |
| Wf, Wu, Wc, Wo | Weights for all the gates | (n_a , n_x + n_a) |
| bf bu bc b0 | Bias term for all operations | (n_a ,1) |
| Wy | Weight for the output | (n_y , n_a) |
| by | Bias term for the output | (n_y ,1) |
Let us now look at how the dimensions of the different outputs evolve after different operations within the LSTM .
Please note that when we do matrix multiplications with two matrices of size ( a,b) * (b,c) we get an output of size (a,c)| Component | Operation | Dimensions |
| Ґf : Forget gate | sigmoid(Wf * [x , a] + bf) | (n_a, n_x + n_a) * (n_x + n_a ,m) + (n_a,1) = > (n_a , m). Sigmoid is applied element wise and therefore dimension doesn’t change. * : denotes matrix multiplication |
| Ґu: Update gate | sigmoid(Wu *[x , a] + bu) | (n_a, n_x+n_a ) * (n_x+n_a,m) + (n_a,1) = > (n_a , m) |
| C~: Input activation | tanh(Wc *[x , a] + bc) | (n_a, n_x + n_a) * (n_x + n_a , m) + (n_a, 1) = > (n_a, m). |
| Ґo : Output gate | (Wo *[x , a] + bo) | (n_a, n_x+n_a ) * (n_x + n_a ,m) + (n_a,1) = > (n_a,m) |
| C<t> : Current state | Ґu x C~ + Ґf x C<t-1> | (n_a, m) x (n_a, m) + (n_a, m) x (n_a, m) = > (n_a, m) x: denotes element wise multiplication |
| a<t> : Output at current time step | tanh(C<t>) x Ґo | (n_a, m) x (n_a, m) => (n_a, m). |
Let us do a toy example with a two time step network with random inputs and observe the dynamics of LSTM.
The network is as defined below with the following inputs for each time steps. We also define the actual outputs for each time step. As you might be aware the actual output will not be relevant during the forward pass, however it will be relevant during the back propogation phase.

Our toy example will have two time steps with its inputs (Xt) having two features as shown in the figure above. For time step 1 the input is Xt-1 = [0.4,0.3] and for time step 2 the input is Xt = [0.2,0.6]. As there are two features, the size of the input unit is n_x = 2. Let us tabulate these values
| Variable | Description | Values | Dimension |
| X t-1 | Input for the first time step | [0.4, 0.3] | (n_x , m) = > (2 ,1) |
| Xt | Input for the second time step | [0.2, 0.6] | (n_x , m) = > (2 ,1) |
For simplicity the hidden layer of the LSTM has only one unit which means that n_a = 1. For the first time step we can assume initial values for the cell state Ct-2 and output from previous layers at-2 as ‘0’.
| Variable | Description | Values | Dimension |
| Ct-2 | Initial cell state | [0] | (n_a , m) = > (1 ,1) |
| at-2 | Initial output from previous cell | [0] | (n_a , m) = > (1 ,1) |
Next we have to define the values for the weights and biases for all the gates. Let us randomly initialize values for the weights. As far as the weights are concerned, what needs to be carefully defined are the dimensions of the weights. In the earlier table where we defined the dimensions of all the components we defined the dimension of the weights as (n_a , n_x + n_a). But why do the weights be with these dimensions ? Let us dig deeper.
From our earlier discussions we know that the weights are used to get the sigmoid gates which are multiplied element wise on the cell states. For example
Ct = Ґu * C~ + Ґf * Ct-1
or
at = tanh(Ct) * Ґo.
From these equations we see that the gates are multiplied element wise to the cell states. To do an element wise multiplication, the gates have to be of the same dimensions as the cell state, i.e. (n_a, m). However, to derive the gates, we need to do a dot product of the initialised weights with the concatenation of previous cell state and the input vector [n_x+n_a]. Therefore to get an output dimension of (n_a, m) we need to have the weights with dimensions of (n_a , n_x + n_a) so that the equation of the gate ,Ґf = sigmoid(Wf *[x , a] + bf), generates an output of dimension of (n_a ,m ). In terms of matrix multiplication dynamics this equation can be represented as below
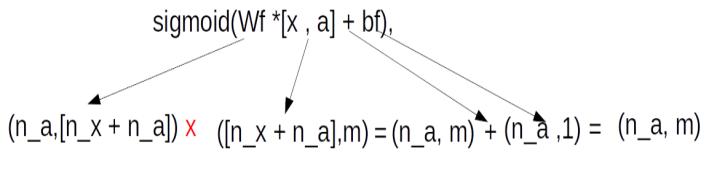
Having seen how the dimensions are derived, let us tabulate the values of weights and its biases .Please note that the values for all the weight matrices and its biases are randomly initialized.
| Weight | Description | Values | Dimension |
| Wf, | Forget gate Weight | [-2.3 , 0.6 , -0.13 ] | [n_a , n_x + n_a] => (1,3) |
| bf | Forget gate bias | [0.51] | [n_a] => 1 |
| Wu | Update gate weight | [1.51 ,-0.61 , 1.31] | [n_a , n_x + n_a] => (1,3) |
| bu | Update gate bias | [1.30] | [n_a] => 1 |
| Wc, | Input activation weight | [0.82,-0.57,-0.13] | [n_a , n_x + n_a] => (1,3) |
| bc | Internal state bias | [-0.57] | [n_a] => 1 |
| Wo | Output gate weight | [-0.75 ,-0.95 , -0.34] | [n_a , n_x + n_a] => (1,3) |
| b0 | Output gate bias | [-0.46] | [n_a] => 1 |
Having defined the initial values and the dimensions let us now traverse through each of the time steps and unravel the numerical example for forward propagation.
Time Step 1 :
Inputs : X t-1 = [0.4, 0.3]
Initial values of the previous state
at-2= [0] ,
Ct-2 = [0]
Forget gate => Ґf = sigmoid(Wf *[x , a] + bf) =>
= sigmoid( [-2.3 , 0.6 , -0.13 ] * [0.4, 0.3, 0] + [0.51] )
= sigmoid(((-2.3 * 0.4) + (0.6 * 0.3) + (-0.13 * 0 )) + 0.51)
= sigmoid(-0.23) = 0.443
Please note sigmoid (-0.23) = 1/(1 + e(-(-0.23))
Update gate => Ґu = sigmoid(Wu *[x , a] + bu) =>
= sigmoid( [1.51 ,-0.61 , 1.31] * [0.4, 0.3, 0] + [1.30] )
= sigmoid((1.51 * 0.4) + (-0.61 * 0.3) + (1.31 * 0 ) + 1.30)
= sigmoid(1.721) = 0.848
Input activation => C~ = tanh(Wc *[x , a] + bc)
= tanh( [0.82,-0.57,-0.13] * [0.4, 0.3, 0] + [-0.57] )
= tanh (((0.82 * 0.4) + (-0.57 * 0.3) + (-0.13 * 0 )) + -0.57)
= tanh(-0.413) = -0.39
Please note tanh = ex – e-x / ( ex + e-x) where x = -0.413
= e-0.413 – e-(-0.413) / ( e-0.413 + e-(-0.413)) = -0.39
Output Gate => Ґo = sigmoid(Wo *[x , a] + bo)
= sigmoid( [-0.75 ,-0.95 , -0.34] * [0.4, 0.3, 0] + [-0.46] )
= sigmoid(((-0.75 * 0.4) + (-0.95 * 0.3) + (-0.34 * 0 )) + -0.46)
= sigmoid(-1.045)= 0.26
We now have all the components required to calculate the internal state and the outputs
Internal state => Ct-1 = Ґu * C~ + Ґf * Ct-2
= 0.848 * -0.39 + 0.443 * 0
= -0.33
Output => at-1 = tanh(Ct-1) * Ґo
= tanh(-0.33) * 0.26 = -0.083
Let us now represent all the numerical values for the first time step on the network.
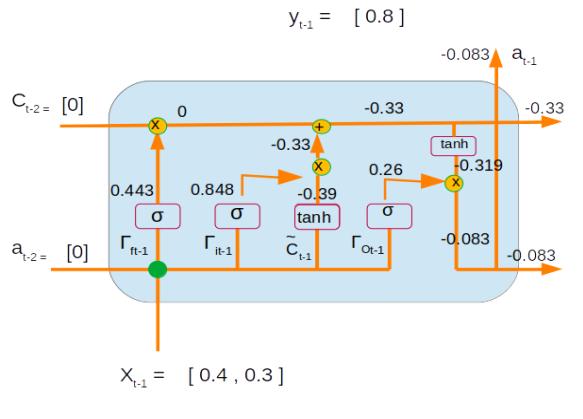
With the calculated values of time step 1 let us proceed to calculating the values of time step 2
Time Step 2:
Inputs : Xt = [0.2, 0.6]
Values of the previous state output and cell states
at-1 = [-0.083]
Ct-1 = [-0.33]
Forget gate => Ґf = sigmoid(Wf *[xt , at-1] + bf) =>
= sigmoid( [-2.3 , 0.6 , -0.13 ] * [0.2, 0.6, -0.083] + [0.51] )
= sigmoid(((-2.3 * 0.2) + (0.6 * 0.6) + (-0.13 * -0.083 )) + 0.51)
= sigmoid(0.421) = 0.60
Update gate => Ґu = sigmoid(Wu *[xt , at-1] + bu) =>
= sigmoid( [1.51 ,-0.61 , 1.31] * [0.2, 0.6, -0.083] + [1.30] )
= sigmoid(((1.51 * 0.2) + (-0.61 * 0.6) + (1.31 * -0.083 )) + 1.30)
= sigmoid(1.13) = 0.755
Input activation => C~ = tanh(Wc *[xt , at-1] + bc)
= tanh( [0.82,-0.57,-0.13] * [0.2, 0.6, -0.083] + [-0.57] )
= tanh(((0.82 * 0.2) + (-0.57 * 0.6) + (-0.13 * -0.083 )) + -0.57)
= tanh(-0.737) = -0.63
Output Gate => Ґo = sigmoid(Wo *[x , a] + bo)
= sigmoid( [[-0.75 ,-0.95 , -0.34] * [0.2, 0.6, -0.083] + [-0.46] )
= sigmoid(((-0.75 * 0.2) + (-0.95 * 0.6) + (-0.34 * -0.083 )) + -0.46)
= sigmoid(-1.15178)= 0.24
Internal state => Ct = Ґu * C~ + Ґf * Ct-1
= 0.755 * -0.63 + 0.60 * -0.33
= -0.674
Output => at = tanh(Ct) * Ґo
= tanh(-0.674) * 0.24 = -0.1410252
Let us now represent the second time step within the LSTM unit

Let us also look at both the time steps together with all its numerical values
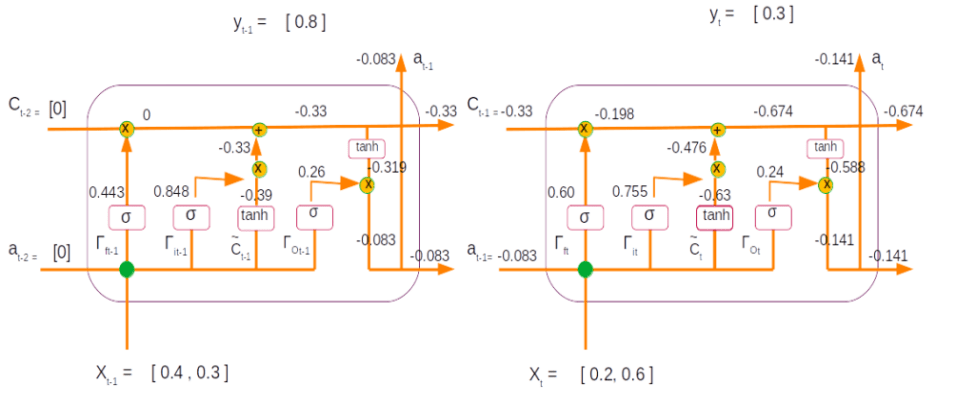
This sums a single forward pass for the LSTM. Once the forward pass is calculated the next step is to determine the error term and the backpropagating the error to determine the adjusted weights and bias terms. We will see those steps in the back propagation steps, which will be covered in the next post.
Go to article 4 of this series : Back propagation of the LSTM unit
Do you want to Climb the Machine Learning Knowledge Pyramid ?
Knowledge acquisition is such a liberating experience. The more you invest in your knowledge enhacement, the more empowered you become. The best way to acquire knowledge is by practical application or learn by doing. If you are inspired by the prospect of being empowerd by practical knowledge in Machine learning, I would recommend two books I have co-authored. The first one is specialised in deep learning with practical hands on exercises and interactive video and audio aids for learning

This book is accessible using the following links
The Deep Learning Workshop on Amazon
The Deep Learning Workshop on Packt
The second book equips you with practical machine learning skill sets. The pedagogy is through practical interactive exercises and activities.

This book can be accessed using the following links
The Data Science Workshop on Amazon
The Data Science Workshop on Packt
Enjoy your learning experience and be empowered !!!!

2 thoughts on “III : Build and Deploy Data Science Products : Looking under the hood of Machine translation model – LSTM Forward Propagation”