

“A sequence works in a way a collection never can”
George Murray
This is the second part of our series on building a machine translation application. In this post we explore sequence to sequence model architecture in greater depth. This series consists of the following eight posts.
- Understand the landscape of solutions available for machine translation
- Explore different sequence to sequence model architecture for machine translation.( This post)
- Deep dive into the LSTM model with worked out numerical example.
- Understand the back propagation algorithm for a LSTM model worked out with a numerical example.
- Build a prototype of the machine translation model using a Google colab / Jupyter notebook.
- Build the production grade code for the training module using Python scripts.
- Building the Machine Translation application -From Prototype to Production : Inference process
- Build the machine translation application using Flask and understand the process to deploy the application on Heroku
In the first part of this series we surveyed the solution landscape of machine translation applications and understood why sequence to sequence models are best suited for machine translation. In this post we will go little deeper and expore architectur choices for sequence to sequence models. We will specifically look at the encoder – decoder architecture which will be the specific architecture we will use for machine translation. We will also get a glimpse of the LSTM model which is the building block for the machine translation application we would be building.
We already know that the problem of machine translation entails deciphering sequence of words in a source language to predict a sequence of target language. For example if you look at the following input German sequence
Ich freue mich darauf, etwas über maschinelle Übersetzung zu lernen.
Which can be translated to I look forward to learning about machine translation
From these sequences we can observe the following.
- The length of input sequence and the length of the target sequence are different
- There is no one to one mapping between words from the input language to the target language
- There is dependence on the context which needs to be learned from the input language to get the best translation for the target language.
The inherent complexities like these in machine translation made models like multi layer perceptron ineffective for machine translation. The need of the hour was a model architecuture which was capable of looking accross sequences of words and understand the context of the source language to effectively translate to the target language. This is where Recurrent Neural Networks (RNNs) became popular for solving machine translation problems. Let us now take a deeper look at RNNs.
Recurrent Neural Networks ( RNNs)
RNN models which fall under the category of Sequence to sequence models are designed to learn the context of any input language. But why is learning the context important ? Let us understand this with a simple example.
Suppose we are predicting the next character in a sequence for the string “Happy B….”. We need to predict the next character after the letter ‘B’. For the time being let us assume that we are ignoring the word “Happy” falling before the letter B. In such a scenario the best bet would be to look for all the words which start with “B” and choose the word which is most frequent. Let us say the most frequent word starting with “B” is the word “Baby”. So the next character which will be predicted would be the letter “a”. Now let us imagine that we started looking at all the characters which preceeds B. Given the information about the preceeding charachters “H”,”A”,”P”,”P”,”Y” “B”, then the probability of predicting ‘i’ would be the highest since the word “Birthday” is the most likely word given the context “Happy B” . This is where the concept of context becomes very significant. Language translation depends a lot on the context and therefore there was the need to adopt an architecture where context was learned. Sequence to sequence models like RNNs became an obvious choice.
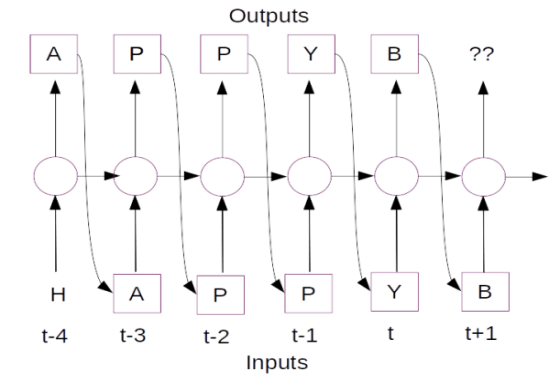
The dynamics of RNN can be represented as above. The circular nodes represents each time step in the sequence. Each of the time steps receives an input represetend as the arrow pointing upwards. In this context each letter in the string becomes the input at each time step. With each character input the output or the prediction is represented at the top. So given the letter ‘H’ the prediction is the letter ‘A’. Once the letter ‘A’ is predicted it becomes the next input and we need to predict the next letter given the context that we had the letter ‘H’ at the previous time step. At each time step we can also see that there is an arrow which points to the right. This is the information or context each time step passes on to the subsequent time step enabling it to predict contextually.
Unlike vanilla neural networks where each layer has a set of parameters, RNNs shares the same parameters accross all the time steps. Because the parameters are shared accross all time steps, the implementation of back propogation is a little different for the case of RNNs. The type of back propogation implemented in RNN is called Back propogation through time(BPTT). We will be covering the dynamics of BPTT with a toy example in the fourth blog of this series.
Earlier we saw that the RNN keeps the context of the previous time steps in memory and applies it when predicting for the time step in consideration. However in practice vanilla RNNs fails when it encounters large sequences. The parameters blow up or shrink to very small values in such cases. These scenarios are called exploding gradients and vanishing gradients respectively. So in practice a RNN can only leaverage few time steps to extract the context. To over come these shortcomings different variations sequence to sequence models are used. One such variation is the LSTM Long Short Term Memory network. We will be using the LSTM network in our application for machine translation. Let us first look at what an LSTM looks like.
Long Short Term Memory Network ( LSTM)
LSTMs, like vanialla RNNs, have the recurrent connections which entails that the context from the previous time steps are passed on to the current time step when generating an output. However we discussed in the previous section on RNN that they suffer from a major problem of exploding or vanishing gradients when encountered with long sequences. This shortcoming was overcome by building a memory block in LSTMs.
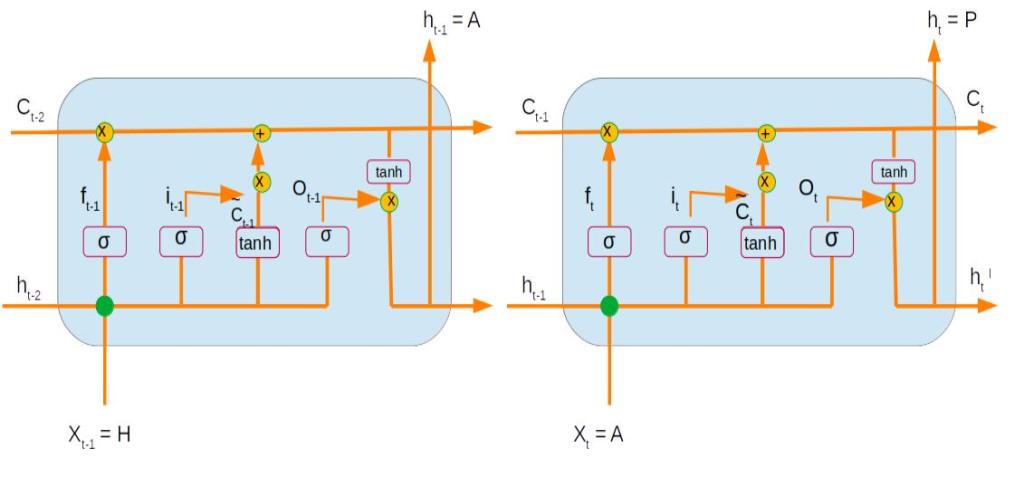
The LSTM has three information sources,two from previous time steps and one from the current time step. The first one is the cell state denoted by ‘Ct’ . The cell state transmits the information about the context from the previous cell states. The second information which passes from the previous layer is its output denoted by ‘ht’. The third is the input for the present time step. In our context of predicting characters, the input from the time step t1 is the letter ‘H’. All these inputs get processed within the LSTM layer enabling it to have memory for longer sequences. We will be having a very detailed worked out example on the dynamics of LSTM in the next post.
An important part of building applications using sequence to sequence models is the selection of right architecture for the use case. Let us now look at different architecture choices for different use cases.
Network Architecture for Sequence to Sequence Models
There are different architecture choices for sequence to sequence models which varies according to the use case. Some of the prominent ones are
- Many to one architecture
This is architecture is ideal for use cases like sentiment analysis where seeing a sequences of words in a string, predict a single output which in this case is the sentiment.

- One to many architecture
This architecture is well suited for use cases like image translation. In such use cases, an image is provided as the input and a sequence of words describing the image is predicted as output. In this case there is one input and multiple outputs.

- Many to many architecture
This is the architecuture which is ideal for a use case like Machine translation. In this architecture, a sequence of words is given as input and the output is also another sequence of words. The below figure is a representation of German to English translation using the many to many architecture.

This architecture is also called Encoder-Decoder architecture. We will see the encoder-decoder architecture in greater depth during our prototype building phase.
Wrapping up
Its now time to wrap up our discussion on sequence to sequence. In this post we had an introduction on RNNs and in specific LSTM which we will be using for the machine translation application. We also looked at different types of architecture choices and identified the encoder-decoder architecture which will be more suited for our use case.
Having seen the conceptual level introduction of sequence to sequence models its time to look under the hood of the LSTM model. In the next post we will work out a toy numerical example and understand in greater depth how LSTM works.
Go to article 3 of the series : Deep dive into the LSTM model with worked out numerical example.
Do you want to Climb the Machine Learning Knowledge Pyramid ?
Knowledge acquisition is such a liberating experience. The more you invest in your knowledge enhacement, the more empowered you become. The best way to acquire knowledge is by practical application or learn by doing. If you are inspired by the prospect of being empowerd by practical knowledge in Machine learning, I would recommend two books I have co-authored. The first one is specialised in deep learning with practical hands on exercises and interactive video and audio aids for learning

This book is accessible using the following links
The Deep Learning Workshop on Amazon
The Deep Learning Workshop on Packt
The second book equips you with practical machine learning skill sets. The pedagogy is through practical interactive exercises and activities.

This book can be accessed using the following links
The Data Science Workshop on Amazon
The Data Science Workshop on Packt
Enjoy your learning experience and be empowered !!!!
