

“To contrive is nothing! To consruct is something ! To produce is everything !”
Edward Rickenbacker
This is the seventh part of the series in which we continue our endeavour in building the inference process for our machine translation application. This series comprises of 8 posts.
- Understand the landscape of solutions available for machine translation
- Explore sequence to sequence model architecture for machine translation.
- Deep dive into the LSTM model with worked out numerical example.
- Understand the back propagation algorithm for a LSTM model worked out with a numerical example.
- Build a prototype of the machine translation model using a Google colab / Jupyter notebook.
- Build the production grade code for the training module using Python scripts.
- Building the Machine Translation application -From Prototype to Production : Inference process ( This post)
- Build the machine translation application using Flask and understand the process to deploy the application on Heroku
In the last post of the series we covered the training process. We built the model and then saved all the variables as pickle files. We will be using the model we developed during the training phase for the inference process. Let us dive in and look at the project structure, which would be similar to the one we saw in the last post.
Project Structure
Let us first look at the helper function file. We will be adding new functions and configuration variables to the file we introduced in the last post.
Let us first look at the configuration file.
Configuration File
Open the configuration file mt_config.py , we used in the last post and add the following lines.
# Define the path where the model is saved
MODEL_PATH = path.sep.join([BASE_PATH,'factoryModel/output/model.h5'])
# Defin the path to the tokenizer
ENG_TOK_PATH = path.sep.join([BASE_PATH,'factoryModel/output/eng_tokenizer.pkl'])
GER_TOK_PATH = path.sep.join([BASE_PATH,'factoryModel/output/deu_tokenizer.pkl'])
# Path to Standard lengths of German and English sentences
GER_STDLEN = path.sep.join([BASE_PATH,'factoryModel/output/ger_length.pkl'])
ENG_STDLEN = path.sep.join([BASE_PATH,'factoryModel/output/eng_length.pkl'])
# Path to the test sets
TEST_X = path.sep.join([BASE_PATH,'factoryModel/output/testX.pkl'])
TEST_Y = path.sep.join([BASE_PATH,'factoryModel/output/testY.pkl'])
Lines 14-23 we add the paths for many of the files and variables we created during the training process.
Line 14 is the path to the model file which was created after the training. We will be using this model for the inference process
Lines 16-17 are the paths to the English and German tokenizers
Lines 19-20 are the variables for the standard lengths of the German and English sequences
Lines 21-23 are the test sets which we will use to predict and evaluate our model.
Utils Folder : Helper functions

Having seen the configuration file, let us now review all the helper functions for the application. In the training phase we created a helper function file called helperFunctions.py. Let us go ahead and revisit that file and add more functions required for the application.
'''
This script lists down all the helper functions which are required for processing raw data
'''
from pickle import load
from numpy import argmax
from pickle import dump
from tensorflow.keras.preprocessing.sequence import pad_sequences
from numpy import array
from unicodedata import normalize
import string
# Function to Save data to pickle form
def save_clean_data(data,filename):
dump(data,open(filename,'wb'))
print('Saved: %s' % filename)
# Function to load pickle data from disk
def load_files(filename):
return load(open(filename,'rb'))
Lines 5-11 as usual are the library packages which are required for the application.
Line 14 is the function to save data as a pickle file. We saw this function in the last post.
Lines 19-20 is a utility function to load a pickle file from disk. The parameter to this function is the path of the file.
In the last post we saw a detailed function for cleaning raw data to finally generate the training and test sets. For the inference process we need an abridged version of that function.
# Function to clean the input data
def cleanInput(lines):
cleanSent = []
cleanDocs = list()
for docs in lines[0].split():
line = normalize('NFD', docs).encode('ascii', 'ignore')
line = line.decode('UTF-8')
line = [line.translate(str.maketrans('', '', string.punctuation))]
line = line[0].lower()
cleanDocs.append(line)
cleanSent.append(' '.join(cleanDocs))
return array(cleanSent)
Line 23 initializes the cleaning function for the input sentences. In this function we assume that the input sentence would be a string and therefore in line 26 we split the string into individual words and iterate through each of the words. Lines 27-28 we normalize the input words to the ascii format. We remove all punctuations in line 29 and then convert the words to lower case in line 30. Finally we join inividual words to a string in line 32 and return the cleaned sentence.
The next function we will insert is the sequence encoder we saw in the last post. Add the following lines to the script
# Function to convert sentences to sequences of integers
def encode_sequences(tokenizer,length,lines):
# Sequences as integers
X = tokenizer.texts_to_sequences(lines)
# Padding the sentences with 0
X = pad_sequences(X,maxlen=length,padding='post')
return X
As seen earlier the parameters are the tokenizer, the standard length and the source data as seen in Line 36.
The sentence is converted into integer sequences using the tokenizer as shown in line 38. The encoded integer sequences are made to standard length in line 40 using the padding function.
We will now look at the utility function to convert integer sequences to words.
# Generate target sentence given source sequence
def Convertsequence(tokenizer,source):
target = list()
reverse_eng = tokenizer.index_word
for i in source:
if i == 0:
continue
target.append(reverse_eng[int(i)])
return ' '.join(target)
We initialize the function in line 44. The parameters to the function are the tokenizer and the source, a list of integers, which needs to be converted into the corresponding words.
In line 46 we define a reverse dictionary from the tokenizer. The reverse dictionary gives you the word in the vocabulary if you give the corresponding index.
In line 47 we iterate through each of the integers in the list . In line 48-49, we ignore the word if the index is 0 as this could be a padded integer. In line 50 we get the word corresponding to the index integer using the reverse dictionary and then append it to the placeholder list created earlier in line 45. All the words which are appended into the placeholder list are then joined together to a string in line 51 and then returned
Next we will review one of the most important functions, a function for generating predictions and the converting the predictions into text form. As seen from the post where we built the prototype, the predict function generates an array which has the same length as the number of maximum sequences and depth equal to the size of the vocabulary of the target language. The depth axis gives you the probability of words accross all the words of the vocabulary. The final predictions have to be transformed from this array format into a text format so that we can easily evaluate our predictions.
# Function to generate predictions from source data
def generatePredictions(model,tokenizer,data):
prediction = model.predict(data,verbose=0)
AllPreds = []
for i in range(len(prediction)):
predIndex = [argmax(prediction[i, :, :], axis=-1)][0]
target = Convertsequence(tokenizer,predIndex)
AllPreds.append(target)
return AllPreds
We initialize the function in line 54. The parameters to the function are the trained model, English tokenizer and the data we want to translate. The data to translate has to be in an array form of dimensions ( num of examples, sequence length).
We generate the prediction in line 55 using the model.predict() method. The predicted output object ( prediction) is an array of dimensions ( num_examples, sequence length, size of english vocabulary)

We initialize a list to store all the predictions on line 56.
Lines 57-58,we iterate through all the examples and then generate the index which has the maximum probability in the last axis of the prediction array. The last axis of the predictions array will be a probability distribution over the words of the target vocabulary. We need to get the index of the word which has the maximum probability. This is what we use the argmax function.
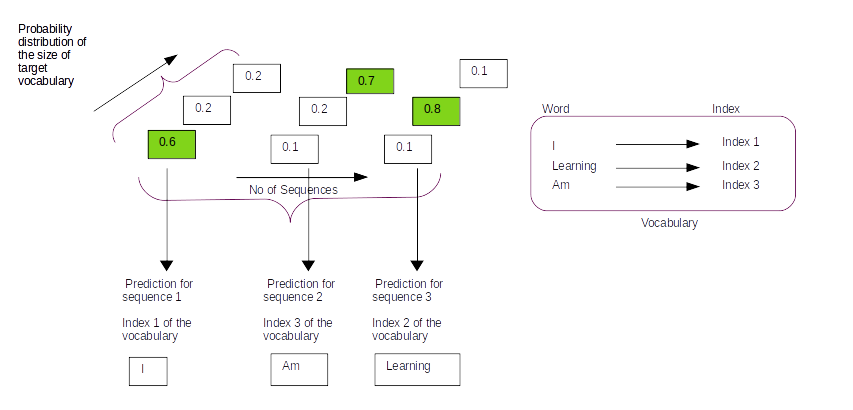
As shown in the representative figure above by taking the argmax of the last axis ( axis = -1) we obtain the index position where the probability of words accross all the words of the vocabulary is the greatest. The output we get from line 58 is a list of the indexes of the vocabulary where the probability is highest as shown in the list below
[ 5, 123, 4, 3052, 0]
In line 59 we convert the above list of integers to a string using the Convertsequence() function we saw earlier. All the predicted strings are then appended to a placeholder list and returned in lines 60-61
Inference Process
Having seen the helper functions, let us now explore the inference process. Let us open a new file and name it mt_Inference.py and enter the following code.
'''
This is the driver file for the inference process
'''
from tensorflow.keras.models import load_model
from factoryModel.config import mt_config as confFile
from factoryModel.utils.helperFunctions import *
## Define the file path to the model
modelPath = confFile.MODEL_PATH
# Load the model from the file path
model = load_model(modelPath)
We import all the required functions in lines 5-7. In line 7 we import all the helper functions we created above. We then initiate the path to the model from the configuration file in line 10.
Once the path to the model is initialized then it is the turn to load the model we saved during the training phase. In line 13 we load the saved model from the path using the Keras function load_model().
Next we load the required pickle files we saved after the training process.
# Get the paths for all the files and variables stored as pickle files
Eng_tokPath = confFile.ENG_TOK_PATH
Ger_tokPath = confFile.GER_TOK_PATH
testxPath = confFile.TEST_X
testyPath = confFile.TEST_Y
Ger_length = confFile.GER_STDLEN
# Load the tokenizer from the pickle file
Eng_tokenizer = load_files(Eng_tokPath)
Ger_tokenizer = load_files(Ger_tokPath)
# Load the standard lengths
Ger_stdlen = load_files(Ger_length)
# Load the test sets
testX = load_files(testxPath)
testY = load_files(testyPath)
On lines 16-20 we intialize the paths to all the files and variables we saved as pickle files during the training phase. These paths are defined in the configuration file. Once the paths are initialized the required files and variables are loaded from the respecive pickle files in lines 22-28. We use the load_files() function we defined in the helper function script for loading the pickle files.
The next step is to generate the predictions for the test set. We already defined the function for generating predictions as part of the helper functions script. We will be calling that function to generate the predictions.
# Generate predictions
predSent = generatePredictions(model,Eng_tokenizer,testX[0:20,:])
for i in range(len(testY[0:20])):
targetY = Convertsequence(Eng_tokenizer,testY[i:i+1][0])
print("Original sentence : {} :: Prediction : {}".format([targetY],[predSent[i]]))
On line 31 we generate the predictions on the test set using the generatePredictions() function. We provide the model , the English tokenizer and the first 20 sequences of the test set for generating the predictions.
Once the predictions are generated let us look at how good our predictions are by comparing it against the original sentence. In line 33-34 we loop through the first 20 target English integer sequences and convert them into the respective English sentences using the Convertsequence() function defined earlier. We then print out our predictions and the original sentence on line 35.

The output will be similar to the one we got during the prototype phase as we havent changed the model parameters during the training phase.
Predicting on our own sentences
When we predict on our own input sentences we have to preprocess the input sentence by cleaning it and then converting it into a sequence of integers. We have already made the required functions for doing that in our helper functions file. The next thing we want is a place to enter the input sentence. Let us provide our input sentence in our configuration file itself.
Let us open the configuration file mt_config.py and add the following at the end of the file.
######## German Sentence for Translation ###############
GER_SENTENCE = 'heute ist ein guter Tag'
In line 27 we define a configuration variable GER_SENTENCE to store the sentences we want to input. We have provided a string 'heute ist ein guter Tag' which means ‘Today is a good day’ as the input string. You are free to input any German sentence you want at this location. Please note that the sentence have to be inside quotes ' '.
Let us now look at how our input sentences can be translated using the inference process. Open the mt_inference.py file and add the following code below the existing code.
############# Prediction of your Own sentences ##################
# Get the input sentence from the config file
inputSentence = [confFile.GER_SENTENCE]
# Clean the input sentence
cleanText = cleanInput(inputSentence)
# Encode the inputsentence as sequence of integers
seq1 = encode_sequences(Ger_tokenizer,int(Ger_stdlen),cleanText)
print("[INFO] .... Predicting on own sentences...")
# Generate the prediction
predSent = generatePredictions(model,Eng_tokenizer,seq1)
print("Original sentence : {} :: Prediction : {}".format([cleanText[0]],predSent))
In line 40 we access the input sentence from the configuration file. We wrap the input string in a list [ ].
In line 43 we do a basic cleaning for the input sentence. We do it using the cleanInput() function we created in the helper function file. Next we encode the cleaned text as integer sequences in line 46. Finally we generate our prediction on line 51 and print out the results in line 52.
Wrapping up
Hurrah!!!! we have come to the end of the inference process. In this post you learned how to generate predictions on the test set. We also predicted our own sentences. We have come a long way and we are ready to make the final lap. Next we will make machine translation application using flask.
You can download the notebook for the inference process using the following link
https://github.com/BayesianQuest/MachineTranslation/tree/master/Production
Do you want to Climb the Machine Learning Knowledge Pyramid ?
Knowledge acquisition is such a liberating experience. The more you invest in your knowledge enhacement, the more empowered you become. The best way to acquire knowledge is by practical application or learn by doing. If you are inspired by the prospect of being empowerd by practical knowledge in Machine learning, I would recommend two books I have co-authored. The first one is specialised in deep learning with practical hands on exercises and interactive video and audio aids for learning

This book is accessible using the following links
The Deep Learning Workshop on Amazon
The Deep Learning Workshop on Packt
The second book equips you with practical machine learning skill sets. The pedagogy is through practical interactive exercises and activities.

This book can be accessed using the following links
The Data Science Workshop on Amazon
The Data Science Workshop on Packt
Enjoy your learning experience and be empowered !!!!

One thought on “VII Build and deploy data science products: Machine translation application – From Prototype to Production for Inference process”