

This is the fifth post of our series on building a self learning recommendation system using reinforcement learning. This post of the series builds on the previous post where we segmented customers using RFM analysis. This series consists of the following posts.
- Recommendation system and reinforcement learning primer
- Introduction to multi armed bandit problem
- Self learning recommendation system as a K-armed bandit
- Build the prototype of the self learning recommendation system : Part I
- Build the prototype of the self learning recommendation system: Part II ( This post )
- Productionising the self learning recommendation system: Part I – Customer Segmentation
- Productionising the self learning recommendation system: Part II – Implementing self learning recommendation
- Evaluating different deployment options for the self learning recommendation systems.
Introduction
In the last post we saw how to create customer segments from transaction data. In this post we will use the customer segments to create states of the customer. Before making the states let us make some assumptions based on the buying behaviour of customers.
- Customers in the same segment have very similar buying behaviours
- The second assumption we will make is that buying pattern of customers vary accross the months. Within each month we are assuming that the buying behaviour within the first 15 days is different from the buying behaviour in the next 15 days. Now these assumptions are made only to demonstrate how such assumptions will influence the creation of different states of the customer. One can still go much more granular with assumptions that the buying pattern changes every week in a month, i.e say the buying pattern within the first week will be differnt from that of the second week and so on. With each level of granularity the number of states required will increase. Ideally such decisions need to be made considering the business dynamics and based on real customer buying behaviours.
- The next assumption we will be making is based on the days in a week. We make an assumption that buying behaviours of customers during different days of a week also varies.
Based on these assumptions, each state will have four tiers i.e
Customer segment >> month >> within first 15 days or not >> day of the week.
Let us now see how this assumption can be carried forward to create different states for our self learning recommendation system.
As a first step towards creation of states, we will create some more variables from the existing variables. We will be using the same dataframe we created till the segmentation phase, which we discussed in the last post.
# Feature engineering of the customer details data frame
# Get the date as a seperate column
custDetails['Date'] = custDetails['Parse_date'].apply(lambda x: x.strftime("%d"))
# Converting date to float for easy comparison
custDetails['Date'] = custDetails['Date'] .astype('float64')
# Get the period of month column
custDetails['monthPeriod'] = custDetails['Date'].apply(lambda x: int(x > 15))
custDetails.head()

Let us closely look at the changes incorporated. In line 3, we are extracting the date of the month and then converting them into a float type in line 5. The purpose of taking the date is to find out which of these transactions have happened before 15th of the month and which after 15th. We extract those details in line 7, where we create a binary points ( 0 & 1) as to whether a date falls in the last 15 days or the first 15 days of the month. Now all data points required to create the state is in place. These individual data points will be combined together to form the state ( i.e. Segment-Month-Monthperiod-Day ). We will getinto nuances of state creation next.
Initialization of values
When we discussed about the K armed bandit in post 2, we saw the functions for generating the rewards and value. What we will do next is to initialize the reward function and the value function for the states.A widely used method for finding the value function and the reward function is to intialize those values to zero. However we already have data on each state and the product buying frequency for each of these states. We will aggregate the quantities of each product as per the state combination to create our initial value functions.
# Aggregate custDetails to get a distribution of rewards
rewardFull = custDetails.groupby(['Segment','Month','monthPeriod','Day','StockCode'])['Quantity'].agg('sum').reset_index()
rewardFull
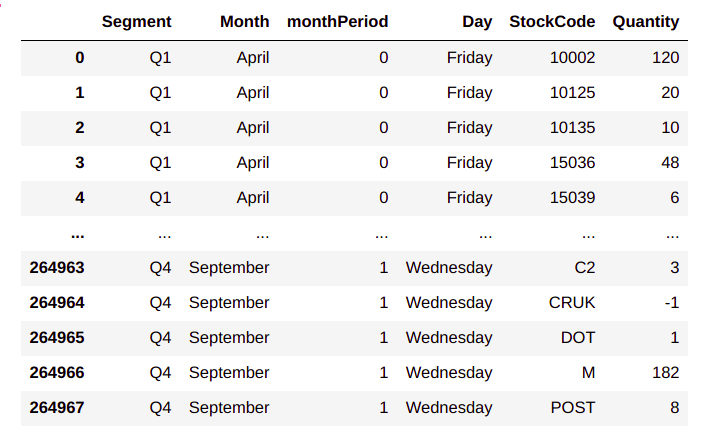
From the output, we can see the state wise distribution of products . For example for the state Q1_April_0_Friday we find that the 120 quantities of product ‘10002’ was bought and so on. So the consolidated data frame represents the propensity of buying of each product. We will make the propensity of buying the basis for the initial values of each product.
Now that we have consolidated the data, we will get into the task of creating our reward and value distribution. We will extract information relevant for each state and then load the data into different dictionaries for ease of use. We will kick off these processes by first extracting the unique values of each of the components of our states.
# Finding unique value for each of the segment
segments = list(rewardFull.Segment.unique())
print('segments',segments)
months = list(rewardFull.Month.unique())
print('months',months)
monthPeriod = list(rewardFull.monthPeriod.unique())
print('monthPeriod',monthPeriod)
days = list(rewardFull.Day.unique())
print('days',days)

In lines 16-22, we take the unique values of each of the components of our state and then store them as list. We will use these lists to create our reward an value function dictionaries . First let us create dictionaries in which we are going to store the values.
# Defining some dictionaries for storing the values
countDic = {} # Dictionary to store the count of products
polDic = {} # Dictionary to store the value distribution
rewDic = {} # Dictionary to store the reward distribution
recoCount = {} # Dictionary to store the recommendation counts
Let us now implement the process of initializing the reward and value functions.
for seg in segments:
for mon in months:
for period in monthPeriod:
for day in days:
# Get the subset of the data
subset1 = rewardFull[(rewardFull['Segment'] == seg) & (rewardFull['Month'] == mon) & (
rewardFull['monthPeriod'] == period) & (rewardFull['Day'] == day)]
# Check if the subset is valid
if len(subset1) > 0:
# Iterate through each of the subset and get the products and its quantities
stateId = str(seg) + '_' + mon + '_' + str(period) + '_' + day
# Define a dictionary for the state ID
countDic[stateId] = {}
for i in range(len(subset1.StockCode)):
countDic[stateId][subset1.iloc[i]['StockCode']] = int(subset1.iloc[i]['Quantity'])
Thats an ugly looking loop. Let us unravel it. In lines 30-33, we implement iterative loops to go through each component of our state, starting from segment, month, month period and finally days. We then get the data which corresponds to each of the components of the state in line 35. In line 38 we do a check to see if there is any data pertaining to the state we are interested in. If there is valid data, then we first define an ID for the state, by combining all the components in line 40. In line 42, we define an inner dictionary for each element of the countDic, dictionary. The key of the countDic dictionary is the state Id we defined in line 40. In the inner dictionary we store each of the products as its key and the corresponding quantity values of the product as its values in line 44.
Let us look at the total number of states in the countDic
len(countDic)
You will notice that there are 572 states formed. Let us look at the data for some of the states.
stateId = 'Q4_September_1_Wednesday'
countDic[stateId]

From the output we can see how for each state, the products and its frequency of purchase is listed. This will form the basis of our reward distribution and also the value distribution. We will create that next
Consolidation of rewards and value distribution
from numpy.random import normal as GaussianDistribution
# Consolidate the rewards and value functions based on the quantities
for key in countDic.keys():
# First get the dictionary of products for a state
prodCounts = countDic[key]
polDic[key] = {}
rewDic[key] = {}
# Update the policy values
for pkey in prodCounts.keys():
# Creating the value dictionary using a Gaussian process
polDic[key][pkey] = GaussianDistribution(loc=prodCounts[pkey], scale=1, size=1)[0].round(2)
# Creating a reward dictionary using a Gaussian process
rewDic[key][pkey] = GaussianDistribution(loc=prodCounts[pkey], scale=1, size=1)[0].round(2)
In line 50, we iterate through each of the states in the countDic. Please note that the key of the dictionary is the state. In line 52, we store the products and its counts for a state, in another variable prodCounts. The prodCounts dictionary has the the product id as its key and the buying frequency as the value,. Lines 53 and 54, we create two more dictionaries for the value and reward dictionaries. In line 56 we loop through each product of the state and make it the key of the inner dictionaries of reward and value dictionaries. We generate a random number from a Gaussian distribution with the mean as the frequency of purchase for the product . We store the number generated from the Gaussian distribution as values for both rewards and value function dictionaries. At the end of the iterations, we get a distribution of rewards and value for each state and the products within each state. The distribution would be centred around the frequency of purchase of each of the product under the state.
Let us take a look at some sample values of both the dictionaries
polDic[stateId]
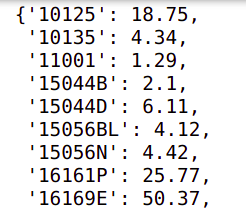
rewDic[stateId]

We have the necessary ingradients for building our selflearning recommendation engine. Let us now think about the actual process in an online recommendation system. In the actual process when a customer visits the ecommerce site, we first need to understand the state of that customer which will be the segment of the customer, the currrent month, which half of the month the customer is logging in and also the day when the customer is logging in. These are the information we would require to create the states.
For our purpose we will simulate the context of the customer using random sampling
Simulation of customer action
# Get the context of the customer. For the time being let us randomly select all the states
seg = sample(['Q1','Q2','Q3','Q4'],1)[0] # Sample the segment
mon = sample(['January','February','March','April','May','June','July','August','September','October','November','December'],1)[0] # Sample the month
monthPer = sample([0,1],1)[0] # sample the month period
day = sample(['Sunday','Monday','Tuesday','Wednesday','Thursday','Friday','Saturday'],1)[0] # Sample the day
# Get the state id by combining all these samples
stateId = str(seg) + '_' + mon + '_' + str(monthPer) + '_' + day
print(stateId)

Lines 64-67, we sample each component of the state and then in line 68 we combine them to form the state id. We will be using the state id for the recommendation process. The recommendation process will have the following step.
Process 1 : Initialize dictionaries
A check is done to find if the value of reward dictionares which we earlier defined has the states which we sampled. If the state exists we take the value dictionary corresponding to the sampled state, if the state dosent exist, we initialise an empty dictionary corresponding to the state. Let us look at the function to do that.
def collfinder(dictionary,stateId):
# dictionary ; This is the dictionary where we check if the state exists
# stateId : StateId to be checked
if stateId in dictionary.keys():
mycol = {}
mycol[stateId] = dictionary[stateId]
else:
# Initialise the state Id in the dictionary
dictionary[stateId] = {}
# Return the state specific collection
mycol = {}
mycol[stateId] = dictionary[stateId]
return mycol[stateId],mycol,dictionary
In line 71, we define the function. The inputs are the dictionary the state id we want to verify. We first check if the state id exists in the dictionary in line 74. If it exists we create a new dictionary called mycol in line 75 and then load all the products and its count to mycol dictionary in line 76.
If the state dosent exist, we first initialise the state in line 79 and then repeat the same processes as of lines 75-76.
Let us now implement this step for the dictionaries which we have already created.
# Check for the policy Dictionary
mypolDic,mypol,polDic = collfinder(polDic,stateId)
Let us check the mypol dictionary.
mypol

We can see the policy dictionary for the state we defined. We will now repeat the process for the reward dictionary and the count dictionaries
# Check for the Reward Dictionary
myrewDic, staterew,rewDic = collfinder(rewDic,stateId)
# Check for the Count Dictionary
myCount,quantityDic,countDic = collfinder(countDic,stateId)
Both these dictionaries are similar to the policy dictionary above.
We also will be creating a similar dictionary for the recommended products, to keep count of all the products which are recommended. Since we havent created a recommendation dictionary, we will initialise that and create the state for the recommendation dictionary.
# Initializing the recommendation dictionary
recoCountdic = {}
# Check the recommendation count dictionary
myrecoDic,recoCount,recoCountdic = collfinder(recoCountdic,stateId)
We will now get into the second process which is the recommendation process
Process 2 : Recommendation process
We start the recommendation process based on the epsilon greedy method. Let us define the overall process for the recommendation system.
As mentioned earlier, one of our basic premise was that customers within the same segment have similar buying propensities. So the products which we need to recommend for a customer, will be picked from all the products bought by customers belonging to that segment. So the first task in the process is to get all the products relevant for the segment to which the customer belongs. We sort the products, in descending order, based on the frequency of product purchase.
Implementing the self learning recommendation system using epsilon greedy process
Next we start the epsion greedy process as learned in post 2, to select the top n products we want to recommend. To begin this process, we generate a random probability distribution value. If the random value is greater than the epsilon value, we pick the first product in the sorted list of products for the segment. Once a product is picked we remove it from the list of products from the segment to ensure that we dont pick it again. This process as we learned when we implemented K-armed bandit problem, is the exploitation phase.
The above was a case when the random probability number was greater than the epsilon value, now if the random probability number is less than the epsilon value, we get into the exploration phase. We randomly sample a product from the universe of products for the segment. Here again we restrict our exploration to the universe of products relevant for the segment. However one could design the exploration ourside the universe of the segment and maybe explore from the basket of all products for all customers.
We continue the exploitation and exploration process till we get the top n products we want. We will look at some of the functions which implements this process.
# Create a function to get a list of products for a certain segment
def segProduct(seg, nproducts,rewardFull):
# Get the list of unique products for each segment
seg_products = list(rewardFull[rewardFull['Segment'] == seg]['StockCode'].unique())
seg_products = sample(seg_products, nproducts)
return seg_products
# This is the function to get the top n products based on value
def sortlist(nproducts, stateId,seg,mypol):
# Get the top products based on the values and sort them from product with largest value to least
topProducts = sorted(mypol[stateId].keys(), key=lambda kv: mypol[stateId][kv])[-nproducts:][::-1]
# If the topProducts is less than the required number of products nproducts, sample the delta
while len(topProducts) < nproducts:
print("[INFO] top products less than required number of products")
segProducts = segProduct(seg,(nproducts - len(topProducts)))
newList = topProducts + segProducts
# Finding unique products
topProducts = list(OrderedDict.fromkeys(newList))
return topProducts
# This is the function to create the number of products based on exploration and exploitation
def sampProduct(seg, nproducts, stateId, epsilon,mypol):
# Initialise an empty list for storing the recommended products
seg_products = []
# Get the list of unique products for each segment
Segment_products = list(rewardFull[rewardFull['Segment'] == seg]['StockCode'].unique())
# Get the list of top n products based on value
topProducts = sortlist(nproducts, stateId,seg,mypol)
# Start a loop to get the required number of products
while len(seg_products) < nproducts:
# First find a probability
probability = np.random.rand()
if probability >= epsilon:
# The top product would be first product in the list
prod = topProducts[0]
# Append the selected product to the list
seg_products.append(prod)
# Remove the top product once appended
topProducts.pop(0)
# Ensure that seg_products is unique
seg_products = list(OrderedDict.fromkeys(seg_products))
else:
# If the probability is less than epsilon value randomly sample one product
prod = sample(Segment_products, 1)[0]
seg_products.append(prod)
# Ensure that seg_products is unique
seg_products = list(OrderedDict.fromkeys(seg_products))
return seg_products
In line 117 we define the function to get the recommended products. The input parameters for the function are the segment, number of products we want to recommend, state id,epsilon value and the policy dictionary . We initialise a list to store the recommended products in line 119 and then extract all the products relevant for the segment in line 121. We then sort the segment products according to frequency of the products. We use the function ‘sortlist‘ in line 104 for this purpose. We sort the value dictionary according to the frequency and then select the top n products in the descending order in line 106. Now if the number of products in the dictionary is less than the number of products we want to be recommended, we randomly select the remaining products from the list of products for the segment. Lines 99-100 in the function ‘segproducts‘ is where we take the list of unique products for the segment and then randomly sample the required number of products and return it in line 110. In line 111 the additional products along with the top products is joined together. The new list of top products are sorted as per the order in which the products were added in line 112 and returned to the calling function in line 123.
Lines 125-142 implements the epsilon greedy process for product recommendation. This is a loop which continues till we get the required number of products for recommending. In line 127 a random probability score is generated and is verified whether it is greater than the epsilon value in line 128. If the random probability score is greater than epsilon value, we extract the topmost product from the list of products in line 130 and then append it to the recommendation candidate product list in line 132. After extraction of the top product, it is removed from the list in line 134. The list is sorted according to the order in which products are added in line 136. This loop continues till we get the required number of products for recommendation.
Lines 137-142 is the loop when the random score is less than the epsilon value i.e exploration stage. In this stage we randomly sample products from the list of products appealing to the segment and append it to the list of recommendation candidates. The final list of candiate products to be recommended is returned in line 143.
Process 3 : Updation of all relevant dictionaries
In the last section we saw the process of selecting the products for recommendation. The next process we will cover is how the products recommended are updated in the relevant dictionaries like quantity dictionary, value dictionary, reward dictionary and recommendation dictionary. Again we will use a function to update the dictionaries. The first function we will see is the one used to update sampled products.
def dicUpdater(prodList, stateId,countDic,recoCountdic,polDic,rewDic):
# Loop through each of the products
for prod in prodList:
# Check if the product is in the dictionary
if prod in list(countDic[stateId].keys()):
# Update the count by 1
countDic[stateId][prod] += 1
else:
countDic[stateId][prod] = 1
if prod in list(recoCountdic[stateId].keys()):
# Update the recommended products with 1
recoCountdic[stateId][prod] += 1
else:
# Initialise the recommended products as 1
recoCountdic[stateId][prod] = 1
if prod not in list(polDic[stateId].keys()):
# Initialise the value as 0
polDic[stateId][prod] = 0
if prod not in list(rewDic[stateId].keys()):
# Initialise the reward dictionary as 0
rewDic[stateId][prod] = GaussianDistribution(loc=0, scale=1, size=1)[0].round(2)
# Return all the dictionaries after update
return countDic,recoCountdic,polDic,rewDic
The inputs for the function are the recommended products ,prodList , stateID, count dictionary, recommendation dictionary, value dictionary and reward dictionary as shown in line 144.
A inner loop is executed in lines 146-166, to go through each product in the product list. In line 148 a check is made to find out if the product is in the count dictionary. This entails, understanding if the product was ever bought under that state. If the product was ever bought before, the count is updated by 1. However if the product was not bought earlier, then the dictionary for that product under that state is initialised as 1 in line 152.
The next step is for updating the recommendation count for the same product. The same logic as above applies. If the product was recommended before, for that state, the number is updated by 1 if not the number is initialised to 1 in lines 153-158.
The next task is to verify if there is a value distribution for this product for the specific state as in lines 159-161. If the value distribution does not exist, it is initialised to zero. However we dont do any updation to the value distribution here. The updation to value distribution happens later on. We will come to that in a moment
The last check is to verify if the product exists in the reward dictionary for that state in lines 162-164. If it dosent exist then it is initialised with a gaussian distribution. Again we dont do any updation for reward as this is done later on.
Now that we have seen the function for updating the dictionaries, we will get into a function which initializes dictionaries. This process is required, if a particular state has never been seen for any of the dictionaries. Let us get to that function
def dicAdder(prodList, stateId,countDic,recoCountdic,polDic,rewDic):
countDic[stateId] = {}
polDic[stateId] = {}
recoCountdic[stateId] = {}
rewDic[stateId] = {}
# Loop through the product list
for prod in prodList:
# Initialise the count as 1
countDic[stateId][prod] = 1
# Initialise the value as 0
polDic[stateId][prod] = 0
# Initialise the recommended products as 1
recoCountdic[stateId][prod] = 1
# Initialise the reward dictionary as 0
rewDic[stateId][prod] = GaussianDistribution(loc=0, scale=1, size=1)[0].round(2)
# Return all the dictionaries after update
return countDic,recoCountdic,polDic,rewDic
The inputs to this function as seen in line 168 are the same as what we saw in the update function. In lines 169-172, we initialise the innner dictionaries for the current state. Lines 174-182, all the inner dictionaries are initialised for the respective products. The count and recommendation dictionaries are initialised by 1 and the value dictionary is intialised as 0. The reward dictionary is initialised using a gaussian distribution. Finally the updated dictionaries are returned in line 184.
Next we start the recommendation process using all the functions we have defined so far.
nProducts = 10
epsilon=0.1
# Get the list of recommended products and update the dictionaries.The process is executed for a scenario when the context exists and does not exist
if len(mypolDic) > 0:
print("The context exists")
# Implement the sampling of products based on exploration and exploitation
seg_products = sampProduct(seg, nProducts , stateId, epsilon,mypol)
# Update the dictionaries of values and rewards
countDic,recoCountdic,polDic,rewDic = dicUpdater(seg_products, stateId,countDic,recoCountdic,polDic,rewDic)
else:
print("The context dosent exist")
# Get the list of relavant products
seg_products = segProduct(seg, nProducts)
# Add products to the value dictionary and rewards dictionary
countDic,recoCountdic,polDic,rewDic = dicAdder(seg_products, stateId,countDic,recoCountdic,polDic,rewDic)
We define the number of products and epsilon values in lines 185-186. In line 189 we check if the state exists which would mean that there would be some products in the dictionary. If the state exists, then we get the list of recommended products using the ‘sampProducts‘ function we saw earlier in line 192. After getting the list of products we update all the dictionaries in line 194.
If the state dosent exist, then products are randomly sampled using the ‘segProduct‘ function in line 198. As before we update the dictionaries in line 200.
Process 4 : Customer Action
So far we have implemented the recommendation process. In real world application, the products we generated are displayed as recommendations to the customer. Based on the recommendations received, the customer carries out different actions as below.
- Customer could buy one or more of the recommended products
- Customer could browse through the recommended products
- Customer could ignore all the recommendations.
Based on the customer actions, we need to give feed back to the online learning system as to how good the recommendations were. Obviously the first scenario is the most desired one, the second one indicates some level of interest and the last one is the undesirable effect. From an self learning perspective we need to reinforce the desirable behaviours and discourage undesirable behavrious by devising proper rewards systems.
Just like we simulated customer states, we will create some functions to simulate customer actions. We define probability distribution to simulate customers propensity for buying a product or clicking a product. Based on the probability distribution we get how many products get bought or how many get clicked. Based on these numbers we sample products from our recommended list as to how many of them are going to be bought or how many would be clicked. Please note that these processes are only required as we are not implementing on a real system. When we are implementing this process in a real system, we get all these feedbacks from the the choices made by the customer.
def custAction(segproducts):
print('[INFO] getting the customer action')
# Sample a value to get how many products will be clicked
click_number = np.random.choice(np.arange(0, 10), p=[0.50,0.35,0.10, 0.025, 0.015,0.0055, 0.002,0.00125,0.00124,0.00001])
# Sample products which will be clicked based on click number
click_list = sample(segproducts,click_number)
# Sample for buy values
buy_number = np.random.choice(np.arange(0, 10), p=[0.70,0.15,0.10, 0.025, 0.015,0.0055, 0.002,0.00125,0.00124,0.00001])
# Sample products which will be bought based on buy number
buy_list = sample(segproducts,buy_number)
return click_list,buy_list
The input to the function is the recommended products as seen from line 201. We then simulate the number of products the customer is going to click using a probability distribution shown in line 204. From the probability distribution we can see there is 50% of chance for not clicking any product, 35% chance to click one product and so on. Once we get the number of products which are likely to be clicked, we sample that many products from the recommended product list. We do a similar process for products that are likely to be bought in lines 209-211. Finally we return the list of products that will be clicked and bought. Please note that there is high likelihood that the returned lists will be empty as the probability distributions are skewed heavily towards that possiblity. Let us implement that function and see what we get.
click_list,buy_list = custAction(seg_products)
print(click_list)
print(buy_list)

So from the simulation, we can see that the customer browsed one product however did not buy any of the products. Please note that you might get a very different simulation when you try as this is a random sampling of products.
Now that we have got the customer action, our next step is to get rewards based on the customer actions. As reward let us define that we will give 5 points if the customer has bought a product and a reward of 1 if the customer has clicked the product and -2 reward if the customer has done neither of these.We will define some functions to update the value dictionaries based on the rewards.
def getReward(loc):
rew = GaussianDistribution(loc=loc, scale=1, size=1)[0].round(2)
return rew
def saPolicy(rew, stateId, prod,polDic,recoCountdic):
# This function gets the relavant algorithm for the policy update
# Get the current value of the state
vcur = polDic[stateId][prod]
# Get the counts of the current product
n = recoCountdic[stateId][prod]
# Calculate the new value
Incvcur = (1 / n) * (rew - vcur)
return Incvcur
def valueUpdater(seg_products, loc,custList,stateId,rewDic,polDic,recoCountdic, remove=True):
for prod in custList:
# Get the reward for the bought product. The reward will be centered around the defined reward for each action
rew = getReward(loc)
# Update the reward in the reward dictionary
rewDic[stateId][prod] += rew
# Update the policy based on the reward
Incvcur = saPolicy(rew, stateId, prod,polDic,recoCountdic)
polDic[stateId][prod] += Incvcur
# Remove the bought product from the product list
if remove:
seg_products.remove(prod)
return seg_products,rewDic,polDic,recoCountdic
The main function is in line 231, whose inputs are the following,
seg_products : segment products we earlier derived
loc : reward for action ( i.e 5 for buy, 1 for browse and -2 for ignoring)
custList : The list of products which are clicked or bought by the customer
stateId : The state ID
rewDic,polDic,recoCountdic : Reward dictionary, value dictionary and recommendation count dictionary for updates
An iterative loop is initiated from line 232 to iterate through all the products in the corresponding list ( buy or click list). First we get the corresponding reward for the action in line 234. This line calls a function defined in line 217, which returns the reward from a Gaussian distribution centred at the reward location ( 5, 1 or -2). Once we get the reward we update the reward dictionary in line 236 with the new reward.
In line 238 we call the function ‘saPolicy‘ for getting the new value for the action. The function ‘saPolicy‘ defined in line 221, takes the reward, state Id , product and dictionaries as input and output the new values for updating the policy dictionary.
In line 224, we get the current value for the state and the product and in line 226 we get the number of times that product was ever selected. The new value is calculated in line 228 through the simple averaging method we dealt with in our post on K armed bandits. The new value is then returned to the calling function and then incremented with the existing value in lines 238-239. To avoid re-recommending the current product for the customer we do a check in line 241 and then remove it from the segment products in line 242. The updated list of segment products along with the updated dictionaries are then returned in line 243.
Let us now look at the implementation of these functions next.
if len(buy_list) > 0:
seg_products,rewDic,polDic,recoCountdic = valueUpdater(seg_products, 5, buy_list,stateId,rewDic,polDic,recoCountdic)
# Repeat the same process for customer click
if len(click_list) > 0:
seg_products,rewDic,polDic,recoCountdic = valueUpdater(seg_products, 1, click_list,stateId,rewDic,polDic,recoCountdic)
# For those products not clicked or bought, give a penalty
if len(seg_products) > 0:
custList = seg_products.copy()
seg_products,rewDic,polDic,recoCountdic = valueUpdater(seg_products, -2, custList,stateId ,rewDic,polDic,recoCountdic, False)
In lines 245,248 and 252 we update the values for the buy list, click list and the ignored products respectively. In the process all the dictionaries also get updated.
That takes us to the end of all the processes for the self learning system. When implementing these processes as system, we have to keep implementing these processes one by one. Let us summarise all the processes which needs to be repeated to build this self learning recommendation system.
- Identify the customer context by simulating the states. In a real life system we dont have to simulate this information as this will be available when a customer logs in
- Initialise the dictionaries for the state id we generated
- Get the list of products to be recommended based on the state id
- Update the dictionaries based on the list of products which were recommended
- Simulate customer actions on the recommended products. Again in real systems we done simulate customer actions as it will be captured online.
- Update the value dictionary and reward dictionary based on customer actions.
All these 6 steps will have to be repeated for each customer instance. Once this cycle runs for some continuous steps, we will get the value dictionaries updated and dynamically aligned to individual customer segments.
What next ?
In this post we built our self learning recommendation system using Jupyter notebooks. Next we will productionise these processes using python scripts. When we productionise these processes, we will also use Mongo DB database to store and retrieve data. We will start the productionising phase in the next post.
Please subscribe to this blog post to get notifications when the next post is published.
You can also subscribe to our Youtube channel for all the videos related to this series.
The complete code base for the series is in the Bayesian Quest Git hub repository
Do you want to Climb the Machine Learning Knowledge Pyramid ?
Knowledge acquisition is such a liberating experience. The more you invest in your knowledge enhacement, the more empowered you become. The best way to acquire knowledge is by practical application or learn by doing. If you are inspired by the prospect of being empowerd by practical knowledge in Machine learning, subscribe to our Youtube channel
I would also recommend two books I have co-authored. The first one is specialised in deep learning with practical hands on exercises and interactive video and audio aids for learning
This book is accessible using the following links
The Deep Learning Workshop on Amazon
The Deep Learning Workshop on Packt
The second book equips you with practical machine learning skill sets. The pedagogy is through practical interactive exercises and activities.

This book can be accessed using the following links
The Data Science Workshop on Amazon
The Data Science Workshop on Packt
Enjoy your learning experience and be empowered !!!!

One thought on “Building Self Learning Recommendation system – V : Prototype Phase II : Self Learning Implementation”