

“Investment in Knowledge pays the best dividend”
Benjamin Franklin
I was searching for a good quote to start this blog and that’s when I came across the above quote by Benjamin Franklin. I think the above quote best sums up what we are going to achieve in this series. We are going to invest our time in gaining an end to end perspective of a use case. We would be embarking on an exciting journey where we will get to experience a machine learning use case in its full glory, right from its theoretical base to building an application and deploying it. Our learning objectives are summed up in the below figure.
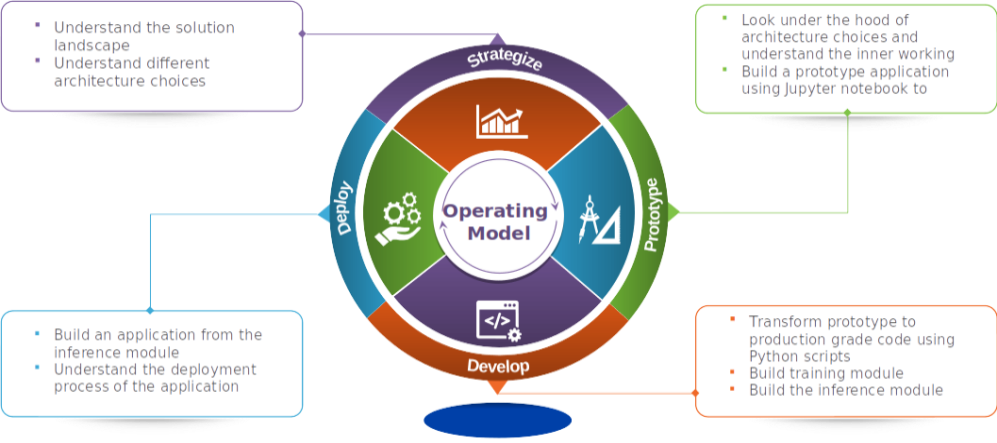
This journey is going to be a 8 post series. In this series we will take a use case, understand the solution landscape and its evolution, explore different architecture choices, look under the hood of the architecture to understand the nuts and bolts, build a prototype, convert the prototype into production ready code, build an application from the production ready code and finally understand the process for deploying the application .The use case we will be dealing with will be Machine Translation. By the end of the series you would have working knowledge on how to build and deploy a Machine translation application, which translates, German sentences into English. This series will comprise of the following posts.
- Understand the landscape of solutions available for machine translation ( This post)
- Explore sequence to sequence model architecture for machine translation.
- Deep dive into the LSTM model with worked out numerical example.
- Understand the back propagation algorithm for a LSTM model worked out with a numerical example.
- Build a prototype of the machine translation model using a Google colab / Jupyter notebook.
- Build the production grade code for the training module using Python scripts.
- Building the Machine Translation application -From Prototype to Production : Inference process
- Build the machine translation application using Flask and understand the process to deploy the application on Heroku
The first four posts lays the theoretical base and in the subsequent 4 posts we will see how the theory can be put to action. You can also watch videos of this series on Youtube.
Let us get started on this journey with an introduction to machine translation.
Introduction to Machine Translation
Language translation has always been a tough nut to crack. What makes it tough is the variations in structure and lexicon when one traverses from one language to the other. For this reason the problem of automated language translation or Machine translation has fascinated and inspired the best minds. Over the past decade some trailblazing advances have happened within this field. We have now reached a stage where machine translation has become quite ubiquitous. These technologies are now embedded in all our devices, mobiles, watches, desktops, tablets etc and have become an integral part of our every day life. A common example is the Google Translate service which has the capability to identify our input languge and subsequently translate it to multitudes of languages.

Machine translation technologies have transcended different approaches before reaching the state we are in at present. Let us take a quick look at the evolution of the solution landscape of machine translation.
Evolution of Solution landscape for Machine Translation
The journey to the current state of the art translation technologies tells a fascinating tale of the strides in machine learning.
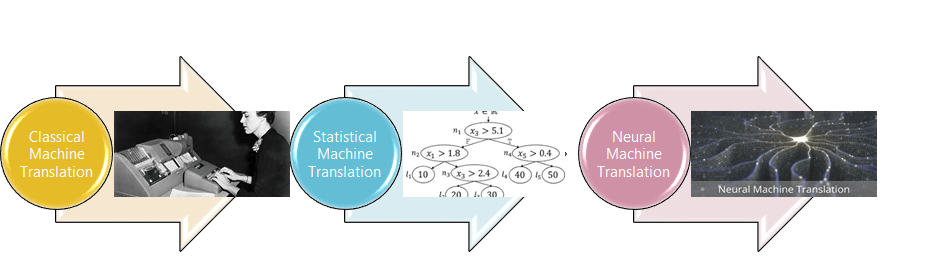
The evolution of machine translation can be demarcated to three distinct phase. Let us look at each one of them and understand its distinct characteristics.
Classical Machine Translation
Classical machine translation methods relies heavily on linguisitc rules and deep domain knowledge to translate from a source language to a target language. There are three approaches under this method.
Direct Translation
“Direct translation is based on a large bilingual dictionary;each entry in the dictionary can be viewed as a small program whose job is to translate one word”
Source : Speech and Language processing : Daniel Jurafsky, James H Martin: 2nd Edition.
As the name suggests this method adopts a word-to-word translation of the source language to the target language. After the word to word translation a re-ordering of the translated words are required based on linguistic rules formulated between the source language and target language.
Let us look at an example
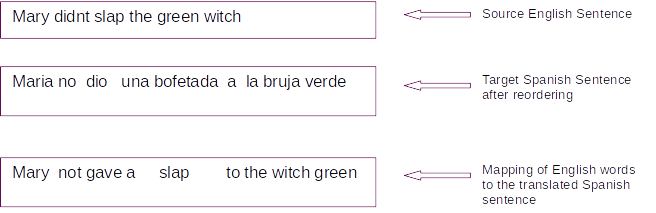
In the above example, the first two boxes represent the source English sentence and the final translated Spanish sentences respectively. The last box is a word to word mapping of the translated Spanish sentence to its English conuterpart. We can see how the word to word translation has been transformed by re-ordering to form a coherent sentence in the target language. These transformations are aided by comprehensive linguistic rules and deep domain knowledge.
Transfer Method
In the example we saw on direct translation method, we saw how the mapping of the English words for the translated Spanish sentence had a complete different ordering from the source English sentence. Every language has such structural charachteristics inherent in them. Transfer methods looks at tapping the structural differences between different language pairs.
Unlike the direct method where there is word to word tranlation followed by re-ordering, transfer methods relies on codification of the contrastive knowledge i.e difference between languages, for translation from the source to the target language. Similar to the direct method, this method also relies on deep domain knowledge and codification of complex rules governing language construction.
Interlingua Method

The intelingua method works on a completely different approach to the word to word and contrastive translations methods we have already seen.
“The interlingua intuition is to treat translation as a process of extracting meaning of the input and then expressing the meaning in the target language.”
SOURCE : Speech and Language processing : Daniel Jurafsky, James H Martin: 2nd Edition.
The intelingua method resonates very closely to the process by which human translators work. When translating , a human translator understands the meaning of the source sentence and translate it to the target language so that the essence of the conversation is not lost. There might not be a word to word mapping of the source sentence and translated sentence. However the meaning would remain intact. This is the principle adopted in the intelingua methods. Like the other two methods in the classical approach, intelingua method also depends on the rich codification of rules and dictionaries
The classical machine translation methods were effective for a large set of use cases. However the classical methods relied on comprehensive set of rules and large dictionaries. Building such knowledge base was a mammoth task requiring specialised skills and expertise. The complexity increased many fold when designing systems able to handle translation of multiple languages. There was a need for an approach different from the domain intensive classical techniques. This led to the rise in popularity of the statistical methods in machine translation.
Statistical Machine Translation
When we explored the classical methods we understood the over dependence on domain knowledge in creating linguistic rules and dictionaries. However it was also a fact that no amount of domain knowledge was enough to handle the intricate nuances of languages. What if phrases, idioms and specialised usages in a language do not have any parallels in another language ? In such circumstances what a linguist would do is to go for the closest match given the source language.
This idea of selecting the most probable sentence in the target languge given a sentence in source language is what is leaveraged in statistical machine translation.
“This provides us with a hint to do Machine Translation. We can model the goal of translation as the production of an output that maximizes some value function that represents the importance of both faithfulness and fluency.”
SOURCE : SPEECH AND LANGUAGE PROCESSING : DANIEL JURAFSKY, JAMES H MARTIN: 2ND EDITION
Statistical methods builds probabilistic models that aims at maximizing the probability of the target sentence which best captures the essence of the source sentence. In probability terms we can represent this as
argmaxT P(T|S)
where T and S are the target and source languages respectively. The above form is the representation of a posterior probability as per Bayes Theorm. This is proportional to
= argmaxT P(S|T) * P(T)
The first term ( P(S|T) ) is called the translation model and can be interpreted as the likelihood of finding the source sentence given the target sentence. The second term P(T) is called the language model which represents the conditional probability of a word in the languge given some preceeding words.
The statistical model aims at finding the conditional probabilities of words within a corpora and using these probabilities find the best possible translation. Statistical machine translation models make use of large corpora or text available on the source and target languages. Eventhough statistical methods were effective, they also had some weaknesses. This method was predominantly focussed on phrases being translated thereby compromising the broder context of the target language. This method struggled when required to translate to a target language which was different in context from the source context. These shortcomings paved the way to advances in other methods which were more robust to retaining the context between the source and target languages.
Neural Machine Translation
Neural machine translation is a different approach where artifical neural networks are used for machine translation. In the statistical machine translation approaches we saw that it uses multiple components like the translation model and language model to do the translations.In NMT models the entire sentence is a single integrated model. In term of approach there isnt drastic deviations from the statistical approaches. However NMTs uses vector representations of words and sentences, which helps in retaining the context of the source and target sentences.
There are different approaches for machine translation using artificial neural networks. One of the earlier approach was to use a multi layer perceptron or a fully connected network for machine translation. However these models werent effective for large sequences of sentences.
Many shortfalls of the earlier approaches were addressed by the adoption of Recurrent Neural network models (RNNs) for machine translation. RNNs are those class of neural networks suited for sequence data. Languages as you know are manifestations of sequence of words with interdependencies between the words within the sequence. RNNs are capable of handling such interdependencies which made such class of models more suited for machine translation. There are different variations of Sequence models which are used for machine translation like encoder-decoder, encoder-decoder with attention etc. We will be using the encoder-decoder models for building our application and will be dealt with in greater depth in the next post.
The state of the art models for machine translation currently are the Transformer models. Transformer models make use of the concept of attention and then builds on it.
Wrapping up the discussions
In this post we introduced the landscape of machine translation approaches. We got introduced to different generations of machine translations solutions starting from the classical approaches,statistical machine translation and neural machine translation approaches.
In the next post we will dive deep into different types of sequence to sequence models and will understand different architecture choices for implementing sequence to sequence models.
We will continue our discussion in the second part of the series which is on sequence to sequence models. See you there.
Do you want to Climb the Machine Learning Knowledge Pyramid ?
Knowledge acquisition is such a liberating experience. The more you invest in your knowledge enhacement, the more empowered you become. The best way to acquire knowledge is by practical application or learn by doing. If you are inspired by the prospect of being empowerd by practical knowledge in Machine learning, I would recommend two books I have co-authored. The first one is specialised in deep learning with practical hands on exercises and interactive video and audio aids for learning

This book is accessible using the following links
The Deep Learning Workshop on Amazon
The Deep Learning Workshop on Packt
The second book equips you with practical machine learning skill sets. The pedagogy is through practical interactive exercises and activities.

This book can be accessed using the following links
The Data Science Workshop on Amazon
The Data Science Workshop on Packt
Enjoy your learning experience and be empowered !!!!
