
JMJPFU
Over the past few months, many people have been asking me to write on what it entails to do a data science project end to end i.e from the business problem defining phase to modelling and its final deployment. When I pondered on that request, I thought it made sense. The data science literature is replete with articles on specific algorithms or definitive methods with code on how to deal with a problem. However an end to end view of what it takes to do a data science project for a specific business use case is little hard to find. From this week onward, we would be starting a new series called the Applied Data Science Series. In this series I would be giving an end to end perspective on tackling business use cases or societal problems within the framework of Data Science. In this first article of the applied data science series we will deal with a predictive maintenance business use case. The use case involved is to predict the end life of large industrial batteries, which falls under the genre of use cases called preventive maintenance use cases.
The big picture
Before we delve deep into the business problem and how to solve it from a data science perspective, let us look at the big picture on the life cycle of a data science project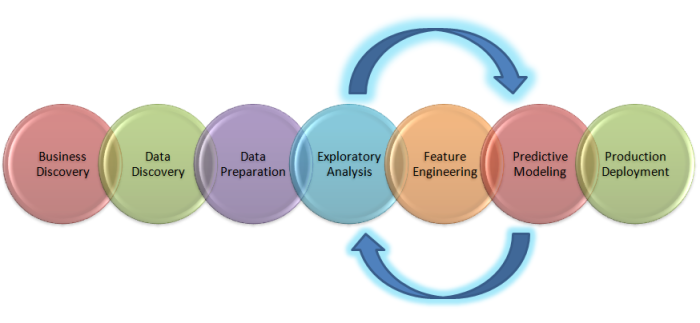 .
.
The above figure is a depiction of the big picture on what it entails to solve a business problem from a Data Science perspective. Let us deal with each of the components end to end.
In the Beginning …… : Business Discovery
The start of any data science project is with a business problem. The problem we have at hand is to try to predict the end life of large industrial batteries. When we are encountered with such a business problem, the first thing which should come to our mind is on the key variables which will come into play . For this specific example of batteries some of the key variables which determine the state of health of batteries are conductance, discharge , voltage, current and temperature.
The next questions which we need to ask is on the lead indicators or trends within these variables, which will help in solving the business problem. This is where we also have to take inputs from the domain team. For the case of batteries, it turns out that a key trend which can indicate propensity for failure is drop in conductance values. The conductance of batteries will drop over time, however the rate at which the conductance values drop will be accelerated before points of failure. This is a vital clue which we will have to be cognizant about when we go for detailed exploratory analysis of the variables.
The other key variable which can come into play is the discharge. When a battery is allowed to discharge the voltage will initially drop to a minimum level and then it will regain the voltage. This is called the “Coup de Fouet” effect. Every manufacturer of batteries will prescribes standards and control charts as to how much, voltage can drop and how the regaining process should be. Any deviation from these standards and control charts would mean anomalous behaviors. This is another set of indicator which will have to look out for when we explore data.
In addition to the above two indicators there are many other factors which one would have to be aware of which will indicate failure. During the business exploration phase we have to identify all such factors which are related to the business problem which we are to solve and formulate hypothesis about them. Once we formulate our hypothesis we have to look out for evidences / trends within the data about these hypothesis. With respect to the two variables which we have discussed above some hypothesis we can formulate are the following.
- Gradual drop in conductance over time would mean normal behavior and sudden drop would mean anomalous behavior
- Deviation from manufactured prescribed “Coup de Fouet” effect would indicate anomalous behavior
When we go about in exploring data, hypothesis like the above will be point of reference in terms of trends which we will have to look out on the variables involved. The more hypothesis we formulate based on domain expertise the better it would be at the exploratory stage. Now that we have seen what it entails within the business discovery phase, let us encapsulate our discussions on key considerations within the business discovery phase
- Understand the business problem which we are set out to solve
- Identify all key variables related to the business problem
- Identify the lead indicators within these variable which will help in solving the business problem.
- Formulate hypothesis about the lead indicators
Once we are equipped with sufficient knowledge about the problem from a business and domain perspective now its time to look at the data we have at hand.
And then came data ……. : Data Discovery
In the data discovery phase we have to try to understand some critical aspects about how data is captured and how the variables are represented within the data sets. Some of the key considerations during the data discovery phase are the following
- Do we have data pertaining to all the variables and lead indicators which we defined during the business discovery phase ?
- What is the mechanism of data capture ? Does the data capture mechanism differ according to the variables ?
- What is the frequency of data capture ? Does it vary across the variables ?
- Does the volume of data captured, vary according to the frequency and variables involved ?
In the case of the battery prediction problem, there are three different data sets . These data sets pertained to different set of variables. The frequency of data collection and the volume of data captured also varies. Some of the key data sets involved are the following
- Conductance data set : Data Pertaining to the conductance of the batteries. This is collected every 2-3 days . Some of the key data points collected along with the conductance data include
- Time stamp when the conductance data was taken
- Unique identifier for each battery
- Other related information like manufacturer , installation location, model , string it was connected to etc
- Terminal voltage data : Data pertaining to Voltage and temperature of battery. This is collected every day. Key data points include
- Voltage of the battery
- Temperature
- Other related information like battery identifier, manufacturer, installation location, model, string data etc
- Discharge Data : Discharge data is collected once every 3 months. Key variable include
- Discharge voltage
- Current at which voltage discharges
- Other related information like battery identifier, manufacturer, installation location, model, string data etc
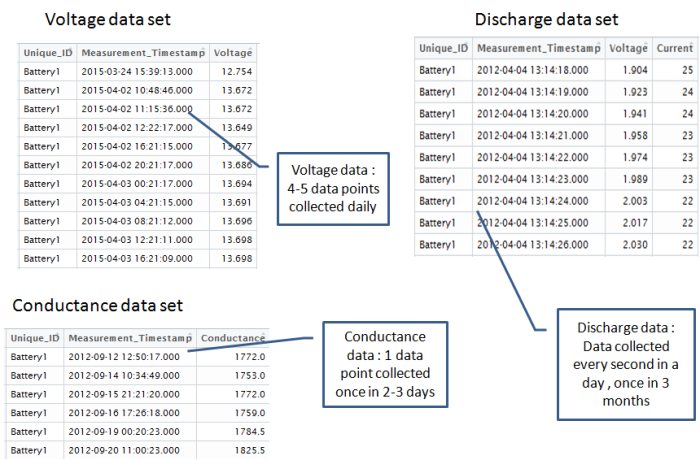
As seen, we have to play around with three very distinct data sets with different sets of variables, different frequency of time when the data points arrive and different volume of data for each of the variables involved. One of the key challenges, one would encounter is in connecting all these variables together into a coherent data set, which will help in the predictive task. It would be easier to get this done if we can formulate the predictive problem by connecting the data sets available to the business problem we are trying to solve. Let us first attempt to formulate the predictive problem.
Formulating the Predictive Problem : Connecting the dots……
To help formulate the predictive problem, let us revisit the business problem we have at hand and then connect it with the data points which we have at hand. The predictive problem requires us to predict two things
- Which battery will fail &
- Which period of time in future will the battery fail.
Since the prediction is at a battery level, our unit of reference for formulating the predictive problem is individual battery. This means that all the variables which are present across the multiple data sets have to be consolidated at the individual battery level.
The next question is, at what period of time do we have to consolidate the variables for each battery ? To answer this question, we will have to look at the frequency of data collection for each variable. In the case of our battery data set, the data points for each of the variables are capture at different intervals. In addition the volume of data collected for each of those variables at those instances of time also vary substantially.
- Conductance : One reading of a battery captured once every 3 days.
- Voltage & Temperature : 4-5 readings per battery captured every day.
- Discharge : A set of reading captured every second at different intervals of a day once every 3 months (approximately 4500 – 5000 data points collected in a day).
Since we have to predict the probability of failure at a period of time in future, we will have to have our model learn the behavior of these variables across time periods. However we have to select a time period, where we will have sufficient data points for each of the variables. The ideal time period we should choose in this scenario is every 3 months as discharge data is available only once every 3 months. This would mean that all the data points for each battery for each variable would have to be consolidated to a single record for every 3 months. So if each battery has around 3 years of data it would entail 12 records for a battery.

Another aspect we have to look at is how 3 months of data points for a battery can be consolidated to make one record corresponding to each variable. For this we have to resort to some suitable form of consolidation metric for each variable. What that consolidation metric should be can be finalized after exploratory analysis and feature engineering . We will deal with those aspects in detail when we talk about exploratory analysis and feature engineering phases.
The next important point which we have to deal with would be the labeling of the response variable. Since the business problem is to predict which battery would fail, the response variable would be classifying whether a record of a battery falls under a failure class or not. However there is a lacunae in this approach. What we want is to predict well ahead of time when a battery is likely to fail and therefore we will have to factor in the “when” part also into the classification task. This would entail, looking at samples of batteries which has actually failed and identifying the point of time when failure happened. We label that point as “failure point” and then look back in time from the failure point to classify periods leading to failure. Since the consolidation period for data points is three months, we can fix the “looking back” period also to be 3 months. This would mean, for those samples of batteries where we know the failure point, we look at the record which is one time period( 3 months) before failure and label the data as 1 period before failure, record of data which corresponds to 6 month before failure will be labelled as 2 periods before failure and so on. We can continue labeling the data according to periods before failure, till we reach a comfortable point in time ahead of failure ( say 1 year). If the comfortable period we have in mind is 1 year, we would have 4 failure classes i.e 1 period before failure, 2 periods before failure, 3 periods before failure and 4 periods before failure. All records before the 1 year period of time can be labelled as “Normal Periods”. This labeling strategy will mean that our predictive problem is a multinomial classification problem, with 5 classes ( 4 failure period classes and 1 normal period class).

The above discussed, labeling strategy is for samples of batteries within our data set which have actually failed and where we know when the failure has happened. However if we do not have information about the list of batteries which have failed and which have not failed, we have to resort to intense exploratory analysis to first determine samples of batteries which have failed and then label them according to the labeling strategy discussed above. We can discuss about how we can use exploratory analysis to identify batteries which have failed, in the next post. Needless to say, the records of all batteries which have not failed, will be labelled as “Normal Periods”.
Now that we have seen the predictive problem formulation part, let us recap our discussions so far. The predictive problem formulation step involves the following
- Understand the business problem and formulate the response variables.
- Identify the unit of reference to which the business problem will apply ( each battery in our case)
- Look at the key variables related to the unit of reference and the volume and velocity at which data for these variables are generated
- Depending on the velocity of data, decide on a data consolidation period and identify the number of records which will be present for the unit of reference.
- From the data set, identify those units which have failed and which have not failed. Such information will generally be available from past maintenance contracts for each units.
- Adopt a labeling strategy for both the failed units and normal units. Identify the number of classes which will be applied to all records of the units. For the failed units, label the records as failed classes till a convenient period( 1 year in this case). All records before that period will be labelled the same as the units which have not failed ( “Normal Periods”)
Wrapping up till we meet again
So far we have discussed the initial two phase of a data science project . The first phase entails defining the business problem and carrying out the business discovery. In the next phase, which is the data discovery phase, we align the available data points to the business problem and then formulate the predictive problem. Once we have a clear understanding of how the predictive problem have to be formulated our next task will be to get into exploratory analysis and feature engineering phases. These phases and the subsequent phases would be dealt in detail in the next post of this series. Watch out this space for more.

You have a well-defined “period”. Why have such a verbose “label” variable, when you could have a nice, succinct “Time to Failure” column. 6 Levels: Undefined, 4, 3, 2, 1, 0. Even better, using this method, you can simply define your failure points and back-propagate (calculate) the other Time To Failure values! In that way, time to failure is a continuous indicator. Even so, you could “bin” that continuous variable to create a categorical response: Normal Operation (>4), Warning Period (4 to 1), and Failure (0). Why go through all the work to hand label if your values aren’t going to be simple, clean and immediately machine readable?
LikeLike
You are right about the labeling part. When we build a model, we will not be using such verbose labels, and will only use some categorical variables like 0,1,2,3 or even introduce a new variable which indicates the period to failure more succinctly. The reason why it was mentioned that way in the article was only to make things clear about the labeling strategy and what each label mean. However at the end of the day during modeling stage we will use categorical variables which are easier for “one hot encoding”.
LikeLike
Hi, tvjoseph
I am very interested in your article, however, it is not finished.
Will you please send me the rest of the post? Look forward,
john
LikeLike
Hi John,
Glad you liked it. I will publish the rest of the piece in a weeks time.
Thomas
LikeLike
Thanks, Thomas.
If the data collected with gaps in between time points, does it affect? what am I trying to predict the when the failure is coming and the possibility of next failure in next 30 days for example. What algorithms can help ? I heard Rest useful time . Seems regression can help.
By the way, I am working in service department which serves machine when fails and perform twice a year preventive maintenance work per machine as well. E..g ATM, money deposit machines, coin deposit ed machines.
Is the unit of reference the individual machine as well?
Do I need to analyse data set on machine basis (one by one?)
Or mix the all data sets of all machines together?
I am kind of confusing .
Please guide me.
Thanks
Can I get your personal email?
John
LikeLike
Hi John,
Need to understand more about your use case before commenting more. My mail id is bayesianquest@gmail.com. You can write to me on this address.
Rgds
Thomas
LikeLike
Hi, Thomas,
My machine log is collected daily, I have corrective maintenance (this is based on Break and Fix basis) and preventive maintenance (this is scheduled by system) data as well. How do I combine them? What I mean is the log is daily, the cm and pm data comes in only when it occurs? If i put them in table format, for example, log data mixed with maintenance data, do I code the data for CM on the dates (e.g. column CM, 1 for CM was done, 0 for No CM job, column PM, 1 for PM job donr, 0 for No PM job)? Am I on the right track?
By the way, there would have parts replaced. Do we include them as well? Like column Part, 1 used, 0 not used. The other column days since last maintenance, e.g. 30 days, etc. Please advise,
Cheers
John
LikeLike
It’s very effortless to find out any topic on web as compared to books, as I found this paragraph at this site.
These are genuinely wonderful ideas in about blogging. You have touched
some nice factors here. Any way keep up wrinting.
I’ve been browsing online more than 3 hours nowadays, but I by no means discovered
any interesting article like yours. It is beautiful price
sufficient for me. In my view, if all site owners and bloggers made just
right content material as you did, the web will probably be
a lot more useful than ever before. http://Cspan.org/
LikeLike